Design Uber
Published:
Overview
This post presents a high-level yet production-grade system design for an Uber-like ride-hailing platform. The design focuses on scalability, low latency, high availability, and real-time geospatial matching while handling massive write throughput for driver location updates.
Functional Requirements
Core Requirements
- Riders must be able to request a ride.
- Drivers must be able to accept or reject ride requests.
- The system must match riders with nearby available drivers.
- Fare estimation and calculation must be supported.
- Real-time driver location tracking must be available.
- The system must manage the complete trip lifecycle (Requested → Matched → In Progress → Completed).
Secondary Requirements
- Surge pricing.
- Rider and driver ratings.
- Scheduled rides.
Non-Functional Requirements
Low Latency (Critical)
Ride matching must occur within seconds. Driver movement updates must appear near real-time on the rider’s map.High Availability
The platform must operate continuously across regions. Regional or node-level failures must not cause system-wide downtime.High Scalability
The system must handle significant traffic spikes during peak hours, bad weather, or large events.- Consistency Trade-offs
- Strong consistency is required for payments and trip state transitions (e.g., ensuring a trip is accepted by only one driver).
- Eventual consistency is acceptable for location data, where minor delays are tolerable.
- Reliability
Once a driver accepts a ride, the system must guarantee that the booking is not lost.
Capacity Estimation
Assumptions
- Total registered users: 300 million
- Daily active riders: 10 million
- Active drivers: 1 million
- Average trips per rider per day: 1
- Total trips per day: 10 million
Traffic Estimation (RPS)
- Seconds per day ≈ 100,000
- Ride request rate ≈ 10,000,000 / 100,000 = ~100 RPS
Location Update Load
- Driver location update frequency: every 5 seconds
- Updates per second:
1,000,000 / 5 = 200,000 writes/sec
Bandwidth Estimation
- Size per location update ≈ 100 bytes
- Total bandwidth ≈ 200,000 × 100 bytes = 20 MB/sec
Storage Estimation
- Trip record size ≈ 1 KB
- Daily trip storage ≈ 10 GB/day
Database Design
1. Persistent Storage (Relational Database)
Rider
- rider_id
- name
- phone
- rating
- payment_method_id
Driver
- driver_id
- name
- phone
- rating
- status (AVAILABLE, BUSY, OFFLINE)
- vehicle_details
Trip
- trip_id
- pickup_location (lat, long)
- drop_location (lat, long)
- driver_id
- rider_id
- start_time
- end_time
- status (REQUESTED, MATCHED, IN_PROGRESS, COMPLETED, CANCELLED)
- fare
Relational databases (e.g., PostgreSQL) are used here for strong consistency and durability.
2. Real-Time Location Storage (In-Memory / NoSQL)
Driver location updates generate extremely high write throughput, which is unsuitable for traditional relational databases.
Driver Location Store (Redis / Cassandra)
- Key: driver_id
- Value: { latitude, longitude, timestamp }
- TTL: 30 seconds
Drivers automatically disappear from the system if updates stop arriving.
3. Geospatial Indexing
Efficiently finding nearby drivers is the core challenge.
Naïve range queries on latitude and longitude do not scale. A spatial index is required.
Supported approaches:
- Geohash: Encodes latitude/longitude into a string. Shared prefixes imply proximity.
- QuadTree: Hierarchical spatial partitioning.
Geospatial Index Table
- Key: geohash
- Value: list of driver_ids in that cell
Redis internally uses geohashing for its geospatial commands.
API Design
1. Request a Ride (Rider)
Endpoint
POST /v1/trips
Headers
Authorization: Bearer <rider_token>
Request Body
{
"pickup_lat": 37.7749,
"pickup_long": -122.4194,
"dropoff_lat": 37.7849,
"dropoff_long": -122.4094,
"service_type": "uberX"
}
Response
{
"trip_id": "7645-8732-abcd",
"status": "SEARCHING",
"estimated_fare": 25.50
}
The response returns immediately with a trip_id while driver matching proceeds asynchronously.
2. Accept a Ride (Driver)
Endpoint
POST /v1/trips/{trip_id}/accept
Headers
Authorization: Bearer <driver_token>
Request Body
{
"driver_id": "8888-9999-xxxx"
}
Response
200 OKon success409 Conflictif another driver accepted the trip first
3. Driver Location Update
Endpoint
POST /v1/driver/location
Request Body
{
"lat": 37.7750,
"long": -122.4195,
"azimuth": 120,
"speed": 45
}
This endpoint handles ~200,000 RPS and must be highly optimized.
Real-Time Location Delivery Architecture
Publish–Subscribe Model
- Drivers publish location updates to the backend.
- Riders receive updates via persistent WebSocket connections.
- The backend acts as a broker between drivers and riders.
Connection Management Layer
Because millions of concurrent WebSocket connections cannot be handled by a single server, a dedicated Push Gateway / Connection Manager layer is introduced.
- Riders maintain WebSocket connections to gateway servers.
- Driver updates arrive at arbitrary backend nodes.
- Updates are propagated via an internal message bus (Redis Pub/Sub or Kafka).
- The appropriate gateway pushes updates to connected riders.
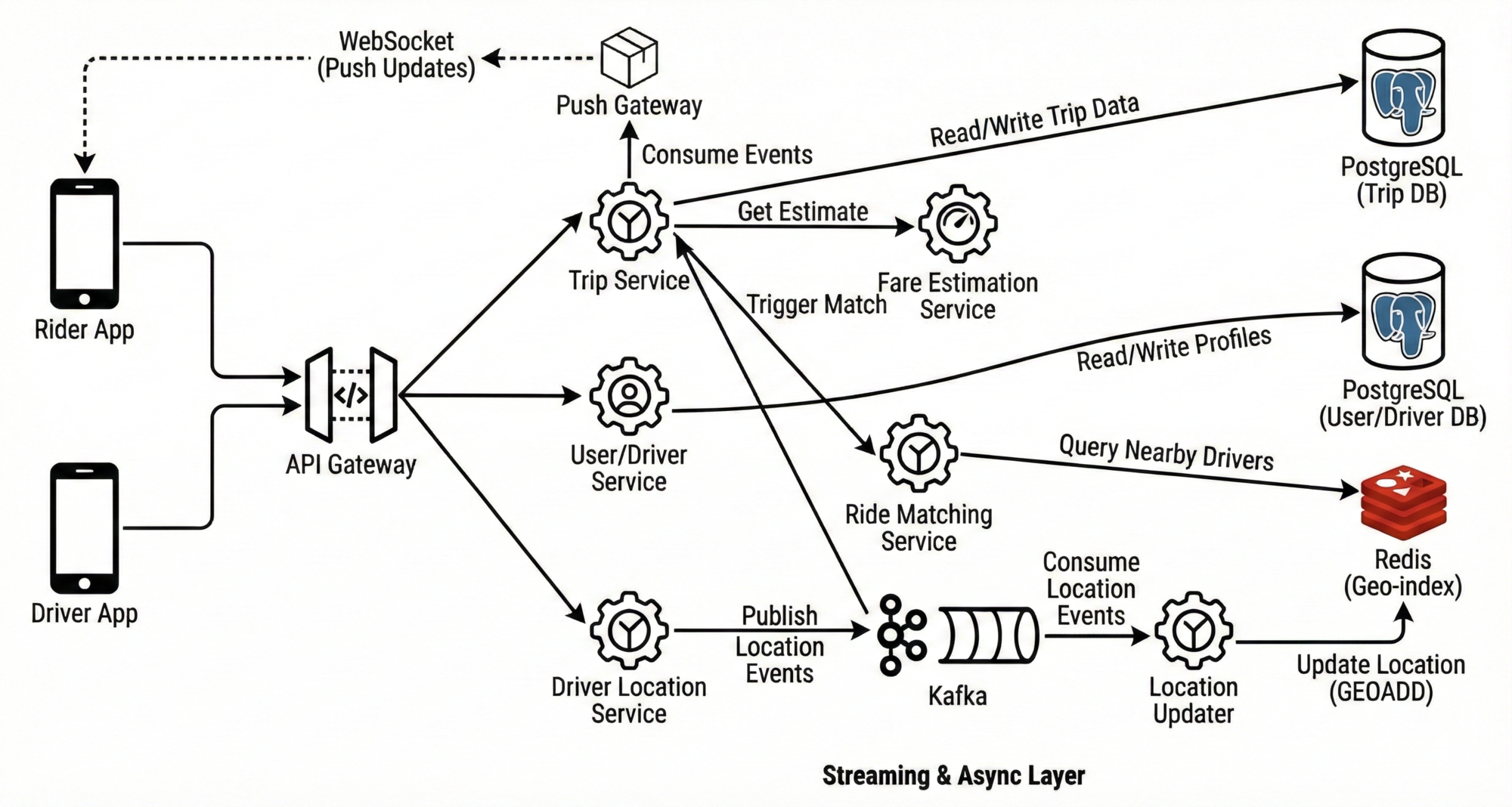
Microservices Architecture
Service Breakdown
- Trip Service
- Manages trip lifecycle and state transitions.
- Ride Matching Service
- Executes geospatial queries to find nearby available drivers.
- User / Driver Service
- Manages profiles, ratings, and metadata (SQL-backed).
- Driver Location Service
- High-throughput ingestion of location updates (Redis-backed).
- Fare Estimation Service
- Calculates the fare of the ride.
This separation avoids shared mutable state and enables independent scaling.
Redis for Location Management
Why Redis?
In-Memory Performance
RAM-based storage enables millions of operations per second with sub-millisecond latency.Native Geospatial Support
Redis provides built-in commands:GEOADD drivers <lon> <lat> <driver_id>GEORADIUS drivers <lon> <lat> <radius> km
These commands eliminate the need for custom geospatial math.
Fault Tolerance and Self-Healing
Redis stores only ephemeral driver location data.
- If Redis crashes, all in-memory location data is lost.
- Drivers resend location updates every 5 seconds.
- The system fully rebuilds accurate state within seconds.
This self-healing behavior makes persistence unnecessary for real-time location data, while all critical data (users, trips, payments) remains safely stored in durable databases.
Kafka-Based Location Pipeline
To further improve scalability and resilience, Apache Kafka is introduced.
Benefits
- Decoupling producers from consumers.
- Buffering during traffic spikes.
- Fan-out to multiple consumers (matching, analytics, fraud detection).
Data Flow
- Driver app → API Gateway
- Ingestion service publishes to Kafka topic (
driver_locations) - Location updater service consumes from Kafka
- Location updater writes to Redis
- Ride Matching Service queries Redis for real-time driver positions
This architecture supports massive scale with strong fault isolation.
Microservices Deep Dive
API Gateway
Responsibilities
- Authentication and authorization (JWT / OAuth)
- Request validation and schema enforcement
- Rate limiting and abuse protection
- Routing requests to backend microservices
Interactions
- Entry point for Rider and Driver apps
- Forwards requests to Trip Service, Driver Location Service, and User / Driver Service
- Contains no business logic
Trip Service
Responsibilities
- Owns the complete trip lifecycle
- Enforces strong consistency for trip state transitions
- Guarantees that a trip can be accepted by only one driver
Owned Data
- Trips table (SQL, transactional)
APIs
POST /v1/tripsPOST /v1/trips/{trip_id}/acceptGET /v1/trips/{trip_id}
Interactions
- Called synchronously by API Gateway
- Triggers Ride Matching Service asynchronously
- Publishes trip updates to Push Gateway
Ride Matching Service
Responsibilities
- Finds the optimal available driver for a trip
- Applies distance, availability, and service-type filters
- Executes geospatial queries
Characteristics
- Stateless
- Horizontally scalable
Interactions
- Reads driver locations from Redis
- Proposes driver assignment to Trip Service
Fare Estimation Service
Responsibilities
- Calculates estimated fare before a ride is booked
- Applies pricing rules based on distance, time, and service type
- Incorporates surge multipliers and dynamic pricing
- Returns a price range to the rider for transparency
Characteristics
- Stateless
- Pure computation service
- Horizontally scalable
Inputs
- Pickup location (lat, long)
- Drop-off location (lat, long)
- Ride type (uberX, uberXL, etc.)
- Current surge multiplier
Outputs
- Estimated fare range
- Pricing breakdown (base fare, distance cost, time cost, surge)
Interactions
- Called synchronously by Trip Service during ride creation
- May query:
- Pricing configuration store
- Surge Pricing component (in-memory or Redis)
Driver Location Service
Responsibilities
- Ingests high-volume driver location updates
- Publishes location events to Kafka
- Maintains real-time driver positions in Redis
Owned Data
- Redis geospatial sets (ephemeral)
Interactions
- Receives traffic via API Gateway
- Produces events to Kafka
- Kafka consumers update Redis using
GEOADD
User / Driver Service
Responsibilities
- Manages rider and driver profiles
- Stores ratings and metadata
- Maintains driver availability status
Owned Data
- Users and drivers (SQL)
Interactions
- Queried by Trip Service and Ride Matching Service
Push Gateway (Connection Manager)
Responsibilities
- Maintains persistent WebSocket connections with riders
- Pushes real-time trip and driver location updates
- Scales independently from core backend services
Interactions
- Consumes events from Kafka or internal message bus
- Delivers updates to connected clients
End-to-End Action Flows
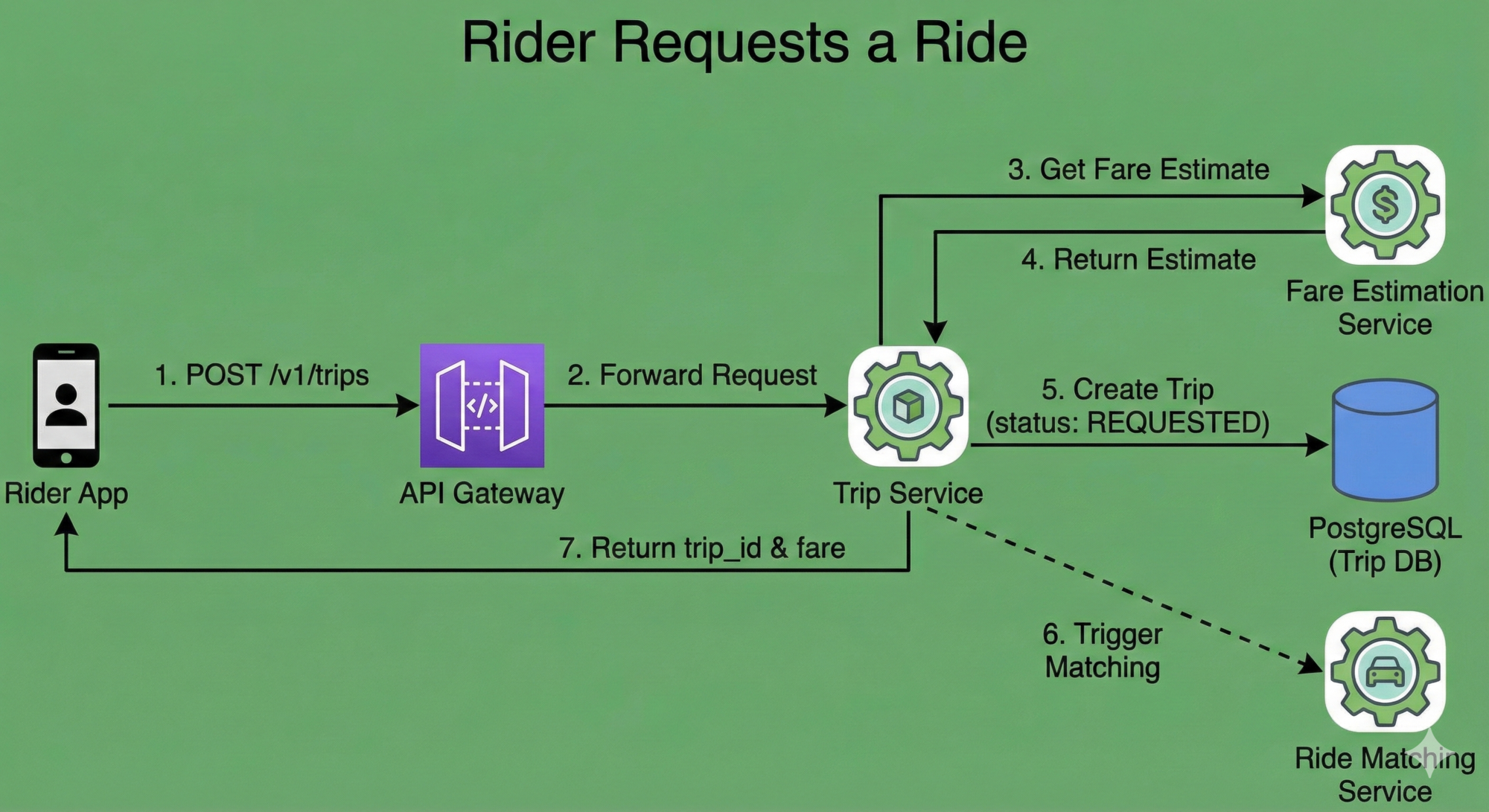
Flow 1: Rider Requests a Ride
Sequence
- Rider App → API Gateway
- API Gateway → Trip Service
- Trip Service → Fare Estimation Service (sync)
- Fare Estimation Service returns estimated fare
- Trip Service persists trip with status
REQUESTED - Trip Service triggers Ride Matching Service asynchronously
Payload Example
{
"pickup_lat": 37.7749,
"pickup_long": -122.4194,
"dropoff_lat": 37.7849,
"dropoff_long": -122.4094,
"service_type": "uberX"
}
{
"trip_id": "7645-8732-abcd",
"status": "SEARCHING",
"estimated_fare": {
"min": 22.00,
"max": 28.50,
"currency": "GBP"
}
}
Logical Diagram
Rider → API Gateway → Trip Service → Ride Matching Service
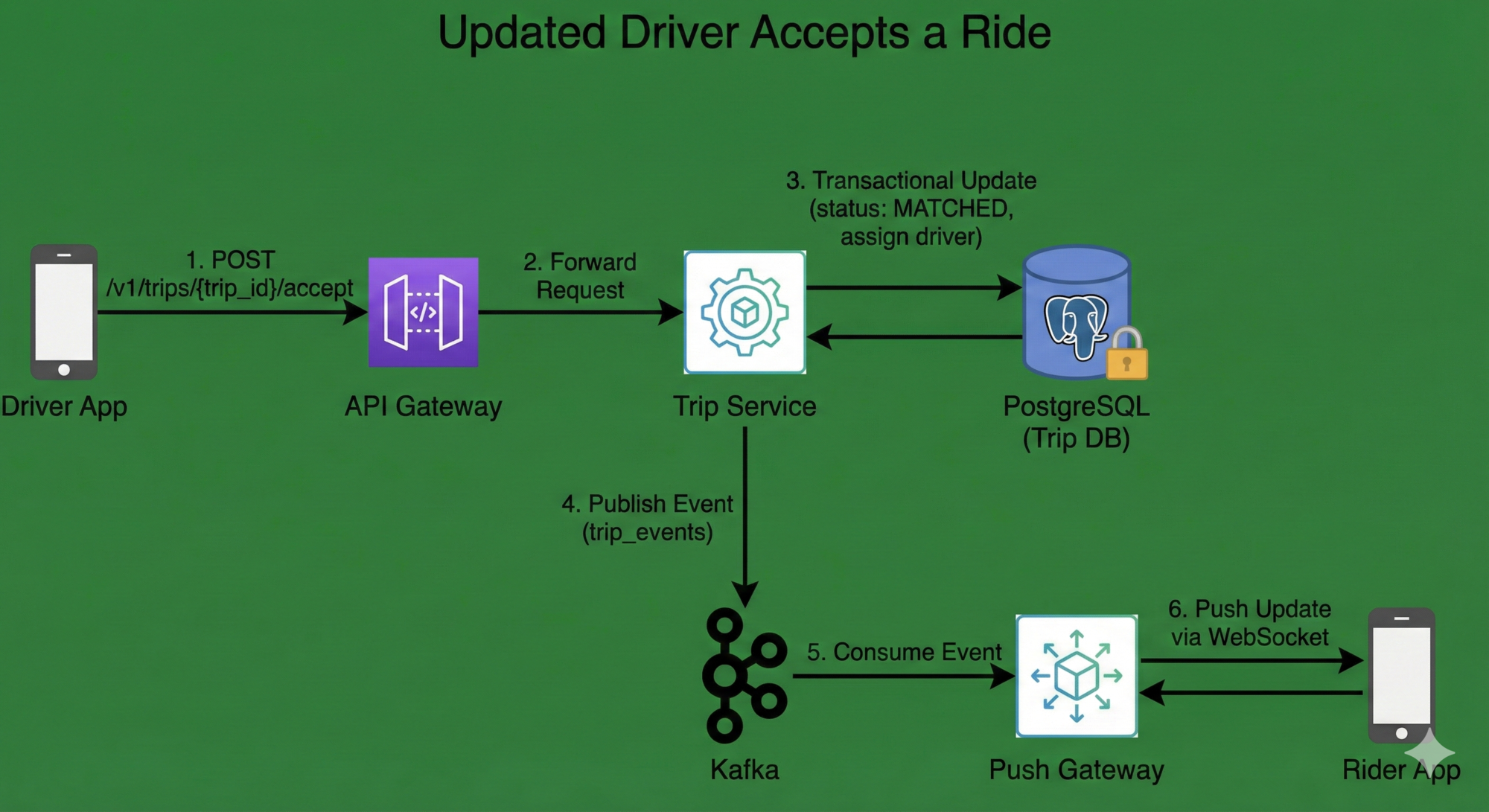
Flow 2: Driver Accepts a Ride
Sequence
- Driver App → API Gateway
- API Gateway → Trip Service
- Trip Service validates request and executes transactional update on Trip DB
- After commit, Trip Service publishes event to
trip_eventstopic - Push Gateway subscribes to event and pushes it directly to Rider App via WebSocket
Payload Example (trip event)
{
"trip_id": "123",
"status": "MATCHED",
"driver_id": "8888-9999",
"rider_id": "456"
}
Logical Diagram
Driver → API Gateway → Trip Service → Kafka → Push Gateway → Rider App
The Sequence of a Status Update (e.g., Driver Accepts Ride)
- Write (The Source of Truth)
- The Driver App sends a
POST /acceptrequest to the Trip Service. - The Trip Service validates the request.
- The Trip Service executes the
UPDATE tripstransaction on PostgreSQL.
- The Driver App sends a
- Notify (The Event)
- Immediately after the database transaction commits successfully, the Trip Service publishes an event to the internal message bus (Kafka or Redis Pub/Sub).
- Topic:
trip_events - Payload:
{ "trip_id": "123", "status": "MATCHED", "rider_id": "456" }
- Push (The Delivery)
- The Push Gateway subscribes to the
trip_eventstopic. - It consumes the event and looks up the active WebSocket connection for
rider_id: 456. - It pushes the payload down the WebSocket to the Rider App.
- The Push Gateway subscribes to the
Notes / Highlights
- PostgreSQL is never read by the Push Gateway
- Push Gateway is stateless, only handles connection and delivery
- Event-driven architecture ensures low latency and high DB scalability
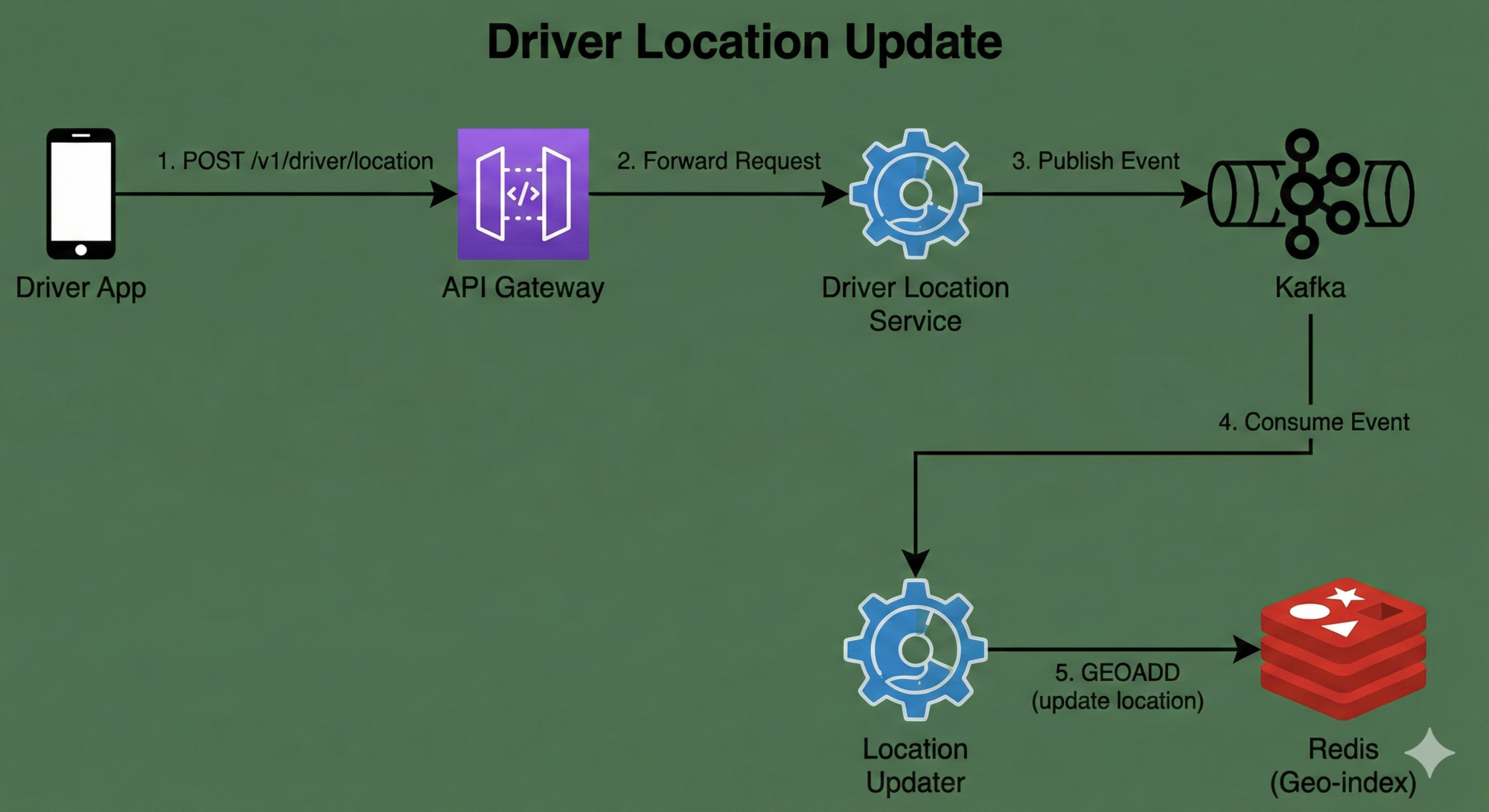
Flow 3: Driver Location Update
Sequence
- Driver App → API Gateway
- API Gateway → Driver Location Service
- Driver Location Service publishes event to Kafka
- Kafka consumer updates Redis using
GEOADD
Logical Diagram
Driver → Gateway → Location Service → Kafka → Redis
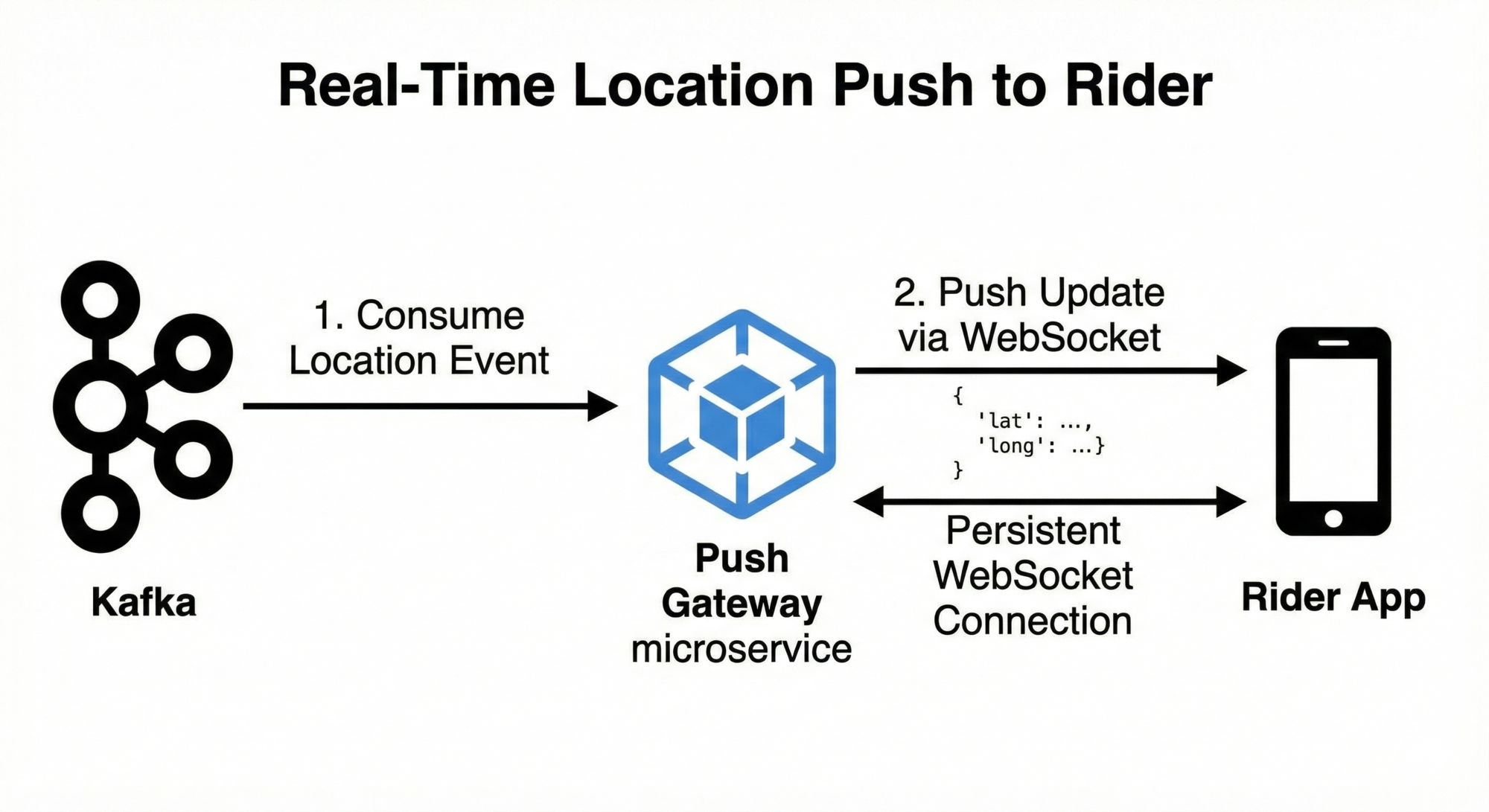
Flow 4: Real-Time Location Push to Rider
Sequence
- Location update consumed from Kafka
- Push Gateway receives update
- Push Gateway sends update via WebSocket to Rider App
Payload Example
{
"driver_id": "d123",
"lat": 37.7750,
"long": -122.4195
}
Why This Architecture Works
- Fare estimation is isolated into a dedicated stateless service, allowing pricing logic to evolve independently from trip state management
- Strong consistency is limited to the Trip Service
- High-throughput paths are asynchronous and event-driven
- Redis stores only ephemeral, self-healing state
- Kafka provides buffering, decoupling, and fan-out
- Each microservice scales independently
Summary
This design demonstrates how Uber-like systems handle:
- Massive real-time data ingestion
- Low-latency geospatial queries
- Event-driven communication
- Ephemeral yet reliable state management
Leave a Comment