Inside Raft: Leader Election, Log Replication, Quorums, and Safety
Published:
1. Introduction
The Problem Raft Solves
Distributed systems often need several machines to behave as if they were one reliable stateful service. A metadata store, configuration system, lock service, scheduler, database replica group, or control plane may all need the same property: each healthy replica must apply the same state changes in the same order.
Raft is a consensus protocol for maintaining that ordered history across a group of servers. It does not define a database, cache, queue, or storage engine by itself. Instead, it provides the replication mechanism that an application can use to keep multiple copies of a state machine consistent.
For a key-value service, the replicated history may contain commands such as:
SET x = 10
SET y = 20
DELETE x
If every replica applies these commands in exactly this order, every replica reaches the same resulting state. If different replicas apply different commands, or apply the same commands in different orders, the service can return inconsistent results.
This is the core abstraction behind Raft:
replicated log -> deterministic state machine -> consistent replicated state
The log is the ordered record of operations. The state machine is the application logic that applies those operations. The replicated state is the result produced by applying the committed log entries.
Consensus Is About Agreement Under Failure
The difficulty is not agreeing when every machine is healthy and every message arrives immediately. The difficulty is preserving agreement when servers crash, restart, fall behind, lose messages, experience disk delays, or become separated by a network partition.
Raft is designed for a crash-fault-tolerant environment. It assumes nodes may stop, restart, or become unreachable, but it does not assume that nodes behave maliciously. A Raft server may fail to respond, but it is not expected to forge messages, lie about its log, or intentionally violate the protocol.
Within that failure model, Raft tries to provide a clear answer to several questions:
- Which server is allowed to accept writes?
- How are writes ordered?
- When is a write considered committed?
- How does a new leader take over without losing committed data?
- How do lagging servers catch up?
- How does the system recover after crashes?
The protocol answers these questions through leader election, replicated logs, terms, majority quorums, and strict rules for choosing leaders.
Common Uses
Raft is commonly used in systems where a small group of trusted servers must agree on metadata or control-plane state. Examples include:
- etcd
- Consul
- Kubernetes control-plane storage through etcd
- distributed databases
- metadata stores
- configuration stores
- lock services
- schedulers and cluster managers
These systems do not usually use Raft to replicate arbitrary files directly. They use Raft to replicate ordered state transitions. Each server stores a log entry, commits it through a quorum, and applies it to its own local state.
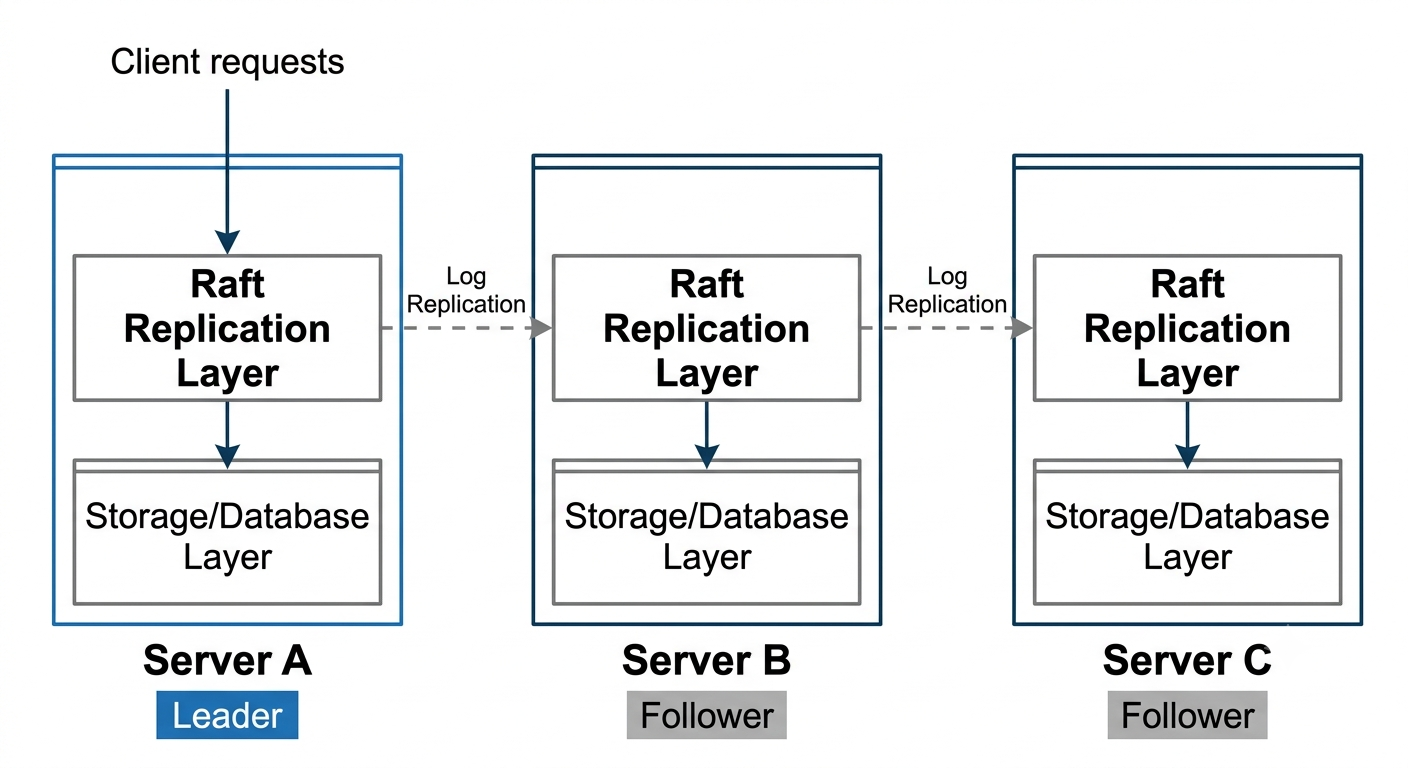
2. The Raft Node Model
Nodes, Servers, and State Machines
A Raft node is usually a server process participating in a Raft group. The process may be part of a larger database, key-value store, metadata service, or control-plane component.
In most production systems, Raft is not deployed as a completely separate database server that sits beside the application database. It is usually an internal replication layer inside the same service process that owns the local state.
Conceptually, each node contains two layers:
database server process
Raft replication layer
storage/database layer
For a small replicated key-value store, three servers may look like this:
Server A: key-value store + Raft
Server B: key-value store + Raft
Server C: key-value store + Raft
The application layer understands commands such as SET, GET, and DELETE. The Raft layer does not need to understand the meaning of those commands. Its responsibility is to make sure the same committed commands reach the application layer in the same order on every server.
The state machine should be deterministic. If two servers start from the same state and apply the same committed commands in the same order, they should produce the same result. Raft depends on this property. It orders operations; it does not repair nondeterministic application behavior.
Local State on Each Node
Each Raft node normally stores several pieces of durable state:
currentTerm
votedFor
log entries
snapshot or compacted state
application state
The exact on-disk layout depends on the implementation, but a simplified storage layout may look like:
raft-log.dat
raft-metadata.dat
snapshot.dat
state.db
The roles of those files are different:
raft-log.dat -> ordered Raft log entries
raft-metadata.dat -> current term and vote state
snapshot.dat -> compacted committed state
state.db -> application state produced by committed entries
The Raft log and the application state are related but not identical. The log records what should happen. The application state records the result after committed entries have been applied.
For example:
Raft log:
1. SET x = 10
2. SET y = 20
3. DELETE x
Application state:
{ y: 20 }
The application state can often be reconstructed by applying the committed log from a snapshot point forward. This distinction matters for crash recovery, replication, and compaction.
Log Entries
A Raft log entry usually contains at least three pieces of information:
index
term
command
The index is the position of the entry in the log. The term identifies the leader election term in which the entry was created. The command is the application operation that will be applied after the entry is committed.
Example:
Index 1, Term 1, Command: SET x = 10
Index 2, Term 1, Command: SET y = 20
Index 3, Term 2, Command: DELETE x
The term is not only metadata for debugging. Raft uses terms to detect stale leaders, compare logs during elections, and resolve conflicting entries after leadership changes.
3. Roles and Terms
The Three Roles
Each Raft node is always in one of three roles:
- A follower accepts requests from leaders and candidates.
- A candidate is trying to become leader.
- A leader accepts client writes and replicates log entries to followers.
At steady state, a Raft group normally has one leader and the remaining nodes are followers:
A = leader
B = follower
C = follower
Clients usually send writes to the leader. If a client contacts a follower, the follower can reject the write or redirect the client to the known leader, depending on the implementation.
The leader is the serialization point for writes. This is a central design choice in Raft. Instead of allowing many servers to propose conflicting orders independently, Raft makes one server responsible for assigning log positions during its leadership term.
Terms
Raft divides time into monotonically increasing terms. A term is a logical epoch, not a wall-clock duration.
Term 1
Term 2
Term 3
...
Each term may have at most one leader. Some terms may have no leader if an election fails because votes are split or the cluster cannot reach a majority.
Every Raft message carries a term. When a node observes a term greater than its own currentTerm, it updates its term and steps down to follower if necessary. This rule lets the cluster move away from stale leadership.
For example:
A believes it is leader in term 4.
B receives a valid message from term 5.
B updates currentTerm to 5.
If B was leader or candidate, B becomes follower.
Higher terms do not mean the node has a more complete log. They mean the node has observed a newer election epoch. Log freshness is checked separately through lastLogIndex and lastLogTerm.
Persistent Election State
Two election-related values are persisted:
currentTerm
votedFor
Persisting currentTerm prevents a restarted node from rejoining the cluster with an outdated view of leadership. Persisting votedFor enforces the rule that a node grants at most one vote per term.
This matters because votes survive crashes. A node should not vote for one candidate, crash, restart, forget the vote, and then vote for a different candidate in the same term. That would weaken Raft’s guarantee that a term can have at most one elected leader.
4. Leader Election
Heartbeats and Election Timeouts
Followers expect to receive periodic messages from the leader. These messages are usually AppendEntries RPCs. When there are no new log entries to replicate, the leader still sends empty AppendEntries messages as heartbeats.
The steady-state flow is:
Leader -> Follower: heartbeat
Leader -> Follower: heartbeat
Leader -> Follower: heartbeat
As long as a follower receives valid leader communication, it remains a follower and resets its election timer.
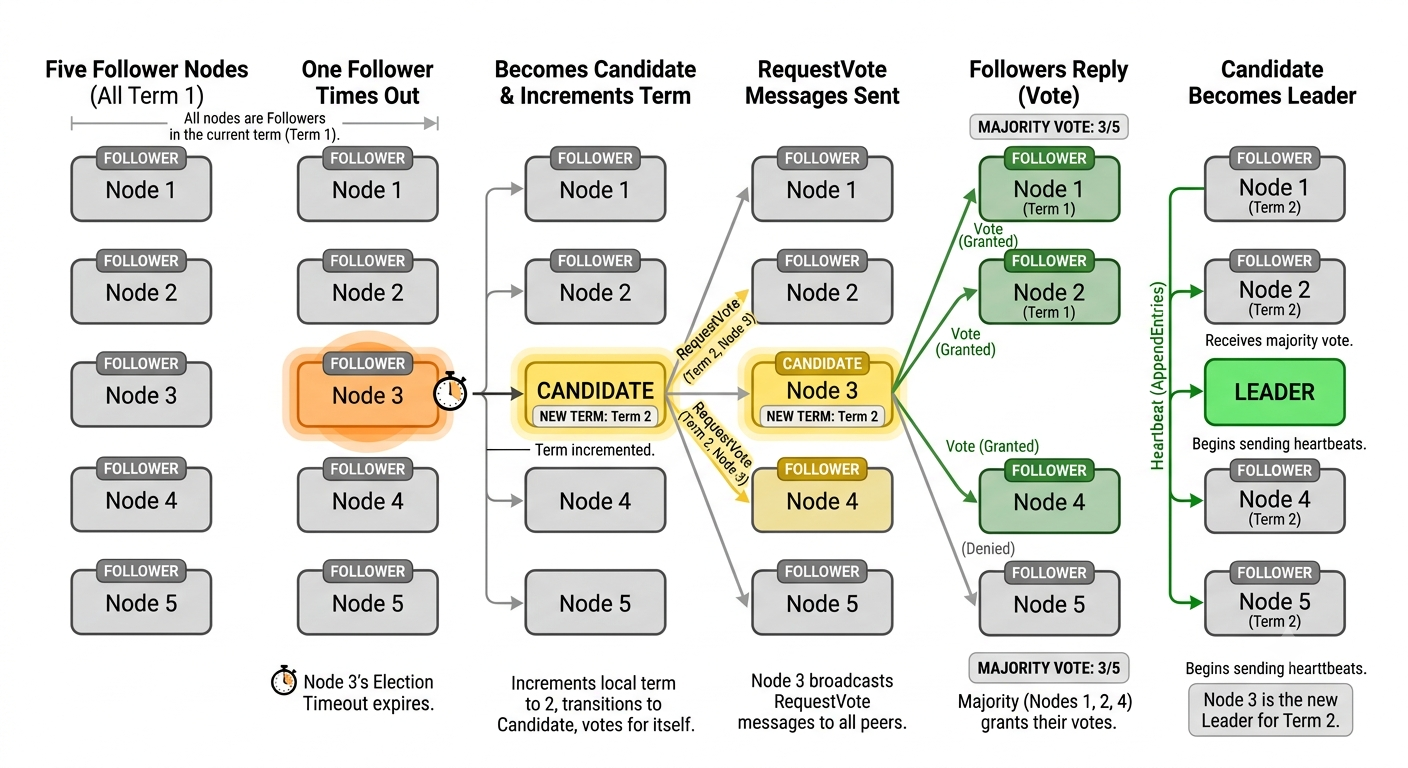
If a follower stops hearing from the leader, its election timeout eventually expires. The follower then becomes a candidate, increments its term, votes for itself, and sends RequestVote RPCs to the other nodes.
follower times out
-> becomes candidate
-> increments term
-> votes for itself
-> requests votes from peers
If the candidate receives votes from a majority of the cluster, it becomes leader.
Majority Requirement
Raft elects leaders by majority vote. In a three-node cluster, a majority is two. In a five-node cluster, a majority is three.
3 nodes -> majority 2
5 nodes -> majority 3
7 nodes -> majority 4
The majority rule is important because any two majorities overlap. In a five-node cluster, any majority of three shares at least one node with any other majority of three. This overlap is the basis for preserving committed entries across leader changes.
If a leader committed an entry on a majority, a future leader must be elected by a majority that overlaps with the old majority. The election rules then ensure that the future leader cannot be missing committed history.
Split Votes
A split vote can occur when multiple followers time out at roughly the same time and become candidates.
For a five-node cluster:
A was leader and crashes.
B, C, D, and E stop receiving heartbeats.
B and C both start elections.
Votes may divide:
B receives votes from B and D.
C receives votes from C and E.
No candidate receives 3 votes.
No leader is elected in that term. The candidates eventually time out again, increment the term, and start another election.
Raft reduces repeated split votes by using randomized election timeouts. Each follower waits a random duration within a configured range. The node that times out first can request votes before the others become candidates.
B timeout = 160 ms
C timeout = 230 ms
D timeout = 190 ms
E timeout = 280 ms
If B times out first, C, D, and E are likely still followers and can vote for B. Once B becomes leader and sends heartbeats, the others reset their timers.
One Vote Per Term
A follower grants at most one vote per term. This rule prevents two candidates in the same term from both collecting a majority in a correctly functioning cluster.
The simplified vote decision is:
if candidate term < currentTerm:
reject vote
if votedFor is empty or votedFor is candidate:
check candidate log freshness
grant vote if candidate log is sufficiently up to date
else:
reject vote
The vote is not granted only because the candidate asks first. The follower also checks whether the candidate’s log is sufficiently up to date. This prevents a server with stale log history from becoming leader and overwriting committed entries.
5. Log Freshness During Elections
The Role of lastLogIndex and lastLogTerm
RequestVote messages include information about the candidate’s last log entry:
lastLogIndex
lastLogTerm
lastLogIndex describes how long the candidate’s log is. lastLogTerm describes the term of the candidate’s last entry.
The two values answer different questions:
lastLogIndex -> how many entries the candidate has
lastLogTerm -> how recent the candidate's last entry is
A longer log is not always more authoritative. A shorter log with entries from a newer term may be more up to date than a longer log whose latest entries came from an older term.
For example:
Candidate A last entry: index 8, term 3
Candidate B last entry: index 6, term 4
Candidate B has fewer entries, but its last entry is from a newer term. According to Raft’s freshness rule, B’s log is more up to date.
The Up-To-Date Rule
A follower treats a candidate’s log as at least as up to date as its own log if:
candidate.lastLogTerm > follower.lastLogTerm
or:
candidate.lastLogTerm == follower.lastLogTerm
and candidate.lastLogIndex >= follower.lastLogIndex
The term comparison is checked first. The index comparison is used only when the last terms are equal.
This rule is central to Raft safety. It prevents a server that is missing committed entries from winning an election if another voter with those committed entries can reject it.
Why currentTerm Is Not Enough
currentTerm records the latest election term a server has observed. It does not prove that the server has the latest log.
A server can have a high currentTerm because it participated in recent failed elections while still missing older committed entries. Raft therefore separates election epoch from log freshness:
currentTerm -> freshness of election knowledge
lastLogTerm -> freshness of log history
lastLogIndex -> length of log history within that term
A candidate must have a current enough term to run in the election and a sufficiently up-to-date log to receive votes.
6. Log Replication
The Write Path
All normal writes flow through the leader. A simplified write in a three-node group proceeds as follows:
1. Client sends command to leader.
2. Leader appends command to its local Raft log.
3. Leader sends AppendEntries to followers.
4. Followers append the entry if it matches their prior log.
5. Followers acknowledge the append.
6. Leader observes that a majority has stored the entry.
7. Leader marks the entry committed.
8. Leader applies the command to its state machine.
9. Leader responds to the client.
10. Followers learn the commit index and apply the entry.
For the command SET x = 10, the log may become:
A log: index 1, term 1, SET x = 10
B log: index 1, term 1, SET x = 10
C log: index 1, term 1, SET x = 10
After the entry is committed, each node applies it to its local state machine:
A state: { x: 10 }
B state: { x: 10 }
C state: { x: 10 }
The important ordering is:
replicate durable log entry
commit after majority acknowledgement
apply committed entry to the state machine
reply success after the command is durable and committed
Implementations may pipeline and batch these operations, but they must preserve the same safety semantics.
AppendEntries Consistency Checks
AppendEntries does not blindly append new data. The leader includes the index and term of the entry that should immediately precede the new entries:
prevLogIndex
prevLogTerm
entries[]
leaderCommit
A follower accepts the append only if its local log contains an entry at prevLogIndex with term prevLogTerm. If that check fails, the follower rejects the request.
This allows the leader to find the point where the follower’s log matches the leader’s log. The leader then overwrites uncommitted conflicting entries on the follower and sends the correct suffix.
For example:
Leader log:
1:a 2:a 3:b 4:b
Follower log:
1:a 2:a 3:c
The logs agree through index 2 and diverge at index 3. The leader backs up until it finds the common prefix, then sends entries from index 3 onward:
Follower corrected log:
1:a 2:a 3:b 4:b
Committed entries are protected by the election rules. The entries overwritten during this process are uncommitted entries from old leaders or failed terms.
Commit Index and Apply Index
Raft distinguishes between entries stored in the log and entries applied to the state machine.
commitIndex -> highest log entry known to be committed
lastApplied -> highest log entry applied to the state machine
An entry can be stored locally before it is committed. It should not be exposed as an applied state-machine change until it is committed.
The leader advances commitIndex when it knows that a log entry from its current term is stored on a majority. Followers learn the leader’s commit index through AppendEntries and apply committed entries in order.
This is why Raft replication is not the same as copying a database file. Raft replicates ordered commands and then applies them. The database state is derived from the committed log.
7. Quorums and Commitment
What a Majority Acknowledgement Means
When a follower acknowledges AppendEntries, it is acknowledging that the relevant log entries have been accepted by that follower according to Raft’s consistency rules. In practical implementations, this usually means the follower has durably recorded the entries before acknowledging, because the follower must survive crashes without forgetting accepted log history.
Raft treats this acknowledgement as truthful within its failure model. A follower may crash, restart, respond slowly, or become unreachable, but the protocol does not attempt to defend against a follower that deliberately claims to have stored an entry when it has not. That behavior belongs to the Byzantine fault model, not the crash fault model used by Raft.
In a three-node cluster:
A = leader
B = follower
C = follower
If A has the entry and B acknowledges it, the entry is stored on two out of three nodes:
A + B = majority
The leader can consider the entry committed once the protocol’s commit conditions are satisfied. It does not need every follower to acknowledge before progress continues.
In a five-node cluster:
A + B + C = majority
D and E may be slow or unavailable
The system can continue as long as a majority is reachable. If only a minority is reachable, the cluster cannot safely commit new writes.
The Leader Does Not Poll for Quorum Separately
The leader does not usually ask a separate question such as “is there quorum?” before every write. It continuously tracks replication progress for each follower.
For each follower, the leader maintains state similar to:
nextIndex -> next log index to send to that follower
matchIndex -> highest log index known to be stored on that follower
As acknowledgements arrive, the leader updates matchIndex. It then computes whether any log index has been replicated to a majority.
For example:
A matchIndex = 10
B matchIndex = 10
C matchIndex = 8
D matchIndex = 10
E matchIndex = 6
Index 10 is present on A, B, and D, so it is present on a majority of five nodes. If it satisfies Raft’s current-term commit rule, the leader can advance the commit index to 10.
Lost Acknowledgements and Leader Crashes
Lost messages do not by themselves make committed data unsafe. If a follower stored an entry but its acknowledgement is lost, the leader may not immediately count that follower. The leader can retry AppendEntries, and the follower can confirm that it already has the entry.
A more subtle case occurs when a leader replicates an entry to a majority and then crashes before notifying all followers that the entry is committed. The entry is still safe if it was replicated according to Raft’s commitment rules. A later leader that is elected through a majority must have, or be able to preserve, the committed history because of quorum overlap and log freshness checks.
The clients may observe temporary uncertainty. A client may not receive a response from the old leader even though the command later becomes committed. Correct clients and services usually handle this by making operations idempotent or by using request identifiers so that retries do not accidentally perform a logical operation twice.
8. Crash Recovery and Write Ordering
Why the Log Comes Before the State Machine
Raft writes commands to the log before applying them to the application state machine. This ordering gives the system a durable source of truth after crashes.
If a server applied a command to its database before the command was committed through Raft, the local state could contain an operation that the cluster later rejects. That would require rollback or complex reconciliation. Raft avoids this by treating committed log entries as the authority.
The simplified rule is:
do not apply an entry to the state machine until it is committed
The local database is therefore downstream of the committed log.
Crash Before Log Append
If the leader crashes before appending the command to its local log, the command has not entered Raft. No replica is required to preserve it.
client sends SET x = 10
leader crashes before log append
The client should not receive a successful commit response. It may retry the command against the new leader.
Crash After Local Append but Before Majority Replication
If the leader appends an entry locally but crashes before replicating it to a majority, the entry is not committed.
A log contains index 5
B and C do not contain index 5
A crashes
A later leader may overwrite that uncommitted entry. This is safe because the entry was never committed. A client that did not receive a success response must treat the outcome as unknown and retry according to the service’s client semantics.
Crash After Majority Replication
If the entry is replicated to a majority before the leader crashes, the entry is protected by the protocol. A later leader must preserve the committed history.
A, B contain index 5 in a three-node cluster
A crashes
B can participate in electing a leader that preserves index 5
The old leader may have crashed before applying the entry locally or before replying to the client. That affects visibility and client retry behavior, but it does not make the committed entry disappear.
Crash After Applying but Before Reply
If the leader commits and applies an entry but crashes before replying, the client may not know whether the command took effect.
leader commits SET x = 10
leader applies SET x = 10
leader crashes before response
From the client’s perspective, the request timed out. From the cluster’s perspective, the command may already be committed. This is not unique to Raft; it is a general distributed-systems problem. Systems built on Raft often use client request IDs, sequence numbers, or idempotent operations to provide exactly-once or effectively-once behavior at the application layer.
9. Lagging Followers, Snapshots, and Compaction
Catching Up a Follower
A follower may fall behind because it was offline, slow, partitioned from the leader, or unable to keep up with the write rate. When it reconnects, the leader uses AppendEntries to bring it back in sync.
The leader starts from the follower’s nextIndex. If the follower rejects the append because the preceding log entry does not match, the leader decreases nextIndex and retries until it finds a matching prefix.
leader tries index 100
follower rejects
leader tries index 90
follower rejects
leader tries index 80
follower accepts
leader sends entries 81 onward
Production implementations optimize this process, but the principle is the same: find the common prefix, then replicate the missing suffix.
Log Growth
A Raft log cannot grow forever without operational cost. If every command remains in the log permanently, disk usage grows continuously and restart recovery becomes slower.
Raft handles this through snapshotting and log compaction. Once a prefix of the log has been committed and applied, the system can create a snapshot of the application state at a specific log index and term.
snapshot includes state through index 10,000
log can retain entries after index 10,000
A simplified snapshot may contain:
lastIncludedIndex
lastIncludedTerm
application state at that index
cluster membership metadata if needed
After the snapshot is safely stored, older log entries covered by the snapshot can be discarded.
Installing Snapshots
If a follower is so far behind that the leader no longer has the old log entries needed to catch it up, the leader sends a snapshot.
follower needs entries from index 2,000
leader compacted log before index 10,000
leader sends snapshot through index 10,000
The follower installs the snapshot, updates its log position, and then receives newer log entries after the snapshot point.
Snapshotting is necessary for long-running systems, but it adds implementation complexity. The system must coordinate snapshot creation, durable storage, log truncation, application state, and follower installation without violating Raft’s ordering rules.
10. Safety Properties
Election Safety
At most one leader can be elected in a given term. This follows from the one-vote-per-term rule and the majority requirement. Two different candidates cannot both receive a majority in the same term because the two majorities would overlap, and the overlapping voter cannot vote for both candidates.
Leader Append-Only Behavior
A leader does not overwrite or delete entries in its own log. It appends new entries. Conflicting entries are resolved on followers when a new leader’s log becomes authoritative.
This simplifies reasoning about the leader’s behavior during a term. Once a leader places an entry at a given index in its own log, it does not replace that entry with another command.
Log Matching
If two logs contain an entry with the same index and term, then the logs are identical in all preceding entries. Raft enforces this through the AppendEntries consistency check.
This property allows a leader and follower to establish a shared prefix and then repair divergence after that prefix.
Leader Completeness
If an entry is committed in a term, that entry will be present in the logs of future leaders. This is one of Raft’s most important safety properties.
The property depends on two mechanisms working together:
- Committed entries are stored on a majority.
- Future leaders must receive votes from a majority and must pass log freshness checks.
Because majorities overlap, at least one voter in a future election has knowledge of the committed entry. The log freshness rule prevents that voter from electing a candidate whose log is missing committed history.
State Machine Safety
If a server applies a log entry at a given index to its state machine, no other server should apply a different command at the same index. This is the practical consistency property that application developers care about.
For example, it should not be possible for one node to apply:
Index 7: SET x = 10
while another applies:
Index 7: DELETE x
Raft’s election and replication rules are designed to prevent that outcome for committed entries.
11. Network Partitions and Availability
Majority Side and Minority Side
During a network partition, a Raft cluster may split into groups that cannot communicate with each other.
In a five-node cluster:
Partition 1: A, B, C
Partition 2: D, E
The first partition has a majority and can elect a leader or continue using its existing leader. The second partition is a minority and cannot safely commit new writes.
This is intentional. If both sides could accept writes independently, they could create conflicting committed histories.
Minority Unavailability
Raft preserves consistency by sacrificing availability on the minority side of a partition. A follower isolated from the leader may start elections, but it cannot win without a majority. A former leader isolated with a minority must step down when it discovers a higher term, and in any case it cannot commit entries without majority replication.
The operational consequence is direct:
no majority -> no new committed writes
This behavior is suitable for systems that prefer correctness of metadata or control-plane state over accepting writes during partitions.
Reads Are Not Automatically Simple
Writes require the leader and a majority. Reads require careful handling too.
A leader may believe it is still leader even after being partitioned away from the majority. If it serves a read from local state without verifying leadership, it may return stale data.
Common approaches include:
- routing reads through the current leader
- using a ReadIndex-style quorum check
- using leader leases with strict clock and timing assumptions
- allowing explicitly stale follower reads for workloads that can tolerate them
Raft gives a foundation for linearizable reads, but implementations must still choose and implement a read policy correctly.
12. Operational Tradeoffs
Single-Leader Throughput
Raft’s single-leader design makes the protocol easier to understand and implement than many multi-proposer designs, but it also concentrates write coordination on one node.
Every committed write must pass through the leader and reach a majority. The leader handles client write traffic, log appends, replication, acknowledgement tracking, commit advancement, and heartbeat traffic.
This makes Raft a strong fit for metadata and control-plane workloads. It may be less suitable for very high write-throughput workloads unless the system shards state across multiple Raft groups.
Majority Latency
A write is not committed when the leader receives it. It is committed after the leader has replicated it to a majority and satisfied the protocol’s commit rule.
The write latency therefore includes:
client -> leader network latency
leader disk append
leader -> followers replication latency
follower disk append
follower -> leader acknowledgement latency
leader apply and response
Batching, pipelining, and efficient storage can reduce the cost, but they do not remove the majority requirement.
Disk Performance
Raft is sensitive to disk behavior because accepted log entries and persistent election state must survive crashes. Slow fsyncs, storage stalls, or noisy disks can increase write latency, delay heartbeats, and trigger unnecessary elections.
For this reason, many Raft-backed systems are operationally sensitive to storage configuration. Consensus is not only a network algorithm; it is also a durable logging system.
Election Instability
Leader election is a temporary unavailability event for writes. During an election, the cluster may reject or delay client requests until a new leader is established.
Election instability can be caused by:
- poorly tuned election timeouts
- long garbage-collection pauses
- disk stalls
- network jitter
- overloaded leaders
- CPU starvation
The timeout range must be long enough to avoid unnecessary elections during normal latency variation, but short enough to recover promptly from a real leader failure.
Dynamic Membership
Changing the membership of a Raft group is more complex than adding a server to a list. The protocol must avoid a transition in which two different configurations can each commit conflicting entries.
Raft handles membership changes through carefully controlled configuration changes, often using joint consensus or related mechanisms. During the transition, the system must reason about quorums from old and new configurations.
Operationally, membership changes should be treated as consensus operations, not as casual process-management events.
Raft Provides Replication, Not a Complete Database
Raft solves agreement on an ordered log. A production database or metadata system still needs many additional components:
- storage engine integration
- snapshot management
- request deduplication
- schema and command validation
- read semantics
- compaction policy
- membership operations
- monitoring and repair tools
- backup and restore
- client retry behavior
Raft is a core replication mechanism, not the entire product architecture.
13. Raft and Byzantine Fault Tolerance
Crash Faults Versus Byzantine Faults
Raft is crash fault tolerant. It assumes servers may crash, restart, become slow, or become unreachable. It does not assume that servers intentionally lie.
Byzantine fault tolerant protocols address a stronger threat model. They assume some participants may be malicious, compromised, or arbitrary in behavior. A Byzantine node may send different messages to different peers, forge invalid statements, or attempt to make honest nodes disagree.
The difference is substantial:
Raft:
nodes are trusted
machines and networks fail
majority is enough
BFT:
some nodes may be malicious
messages may be deceptive
additional voting and verification are required
This stronger model changes the replica count required for safety. A common BFT threshold is 3f + 1 replicas to tolerate f Byzantine replicas. Under that model, tolerating one malicious replica requires four replicas, and tolerating two malicious replicas requires seven. Raft does not use this threshold because it is not solving the same failure model.
For many company-internal systems, Raft’s threat model is appropriate. The system operator controls the nodes and primarily needs protection against crashes, partitions, restarts, and slow machines.
Where BFT Is Used
BFT protocols are useful when the participants are controlled by different organizations or when compromise must be part of the fault model.
Examples include:
- blockchains
- inter-organization ledgers
- supply-chain audit systems
- some critical signing systems
- multi-party infrastructure where operators do not fully trust each other
Protocols such as Tendermint/CometBFT, HotStuff-style protocols, and SmartBFT-style systems are designed for these environments.
BFT protocols usually require more messages, more verification, and more operational complexity than Raft. That cost is justified only when the stronger threat model is required.
14. End-to-End Example
Consider a three-node key-value store:
Server A
Server B
Server C
Each server contains:
Raft layer
local key-value state machine
Assume A is the leader in term 1. The initial application state is empty:
A state: {}
B state: {}
C state: {}
A client sends:
SET x = 10
The write proceeds as follows:
1. Client sends SET x = 10 to A.
2. A appends index 1, term 1, SET x = 10 to its log.
3. A sends AppendEntries to B and C.
4. B validates the previous log position, appends the entry, and replies success.
5. A now has the entry on A and B.
6. A observes a majority of 2 out of 3.
7. A advances its commit index to 1.
8. A applies SET x = 10 to its local state machine.
9. A replies success to the client.
10. C receives the entry or learns the commit index later and applies it.
After convergence, the logs contain the same committed entry:
A log: [1: term 1, SET x = 10]
B log: [1: term 1, SET x = 10]
C log: [1: term 1, SET x = 10]
The state machines have the same state:
A state: { x: 10 }
B state: { x: 10 }
C state: { x: 10 }
The service is replicated because the command was ordered through the log, committed through a majority, and applied consistently by each node.
15. Summary
Raft is a consensus protocol for replicating an ordered log across a group of trusted servers. The application using Raft supplies the state machine; Raft supplies leader election, log replication, commitment, and safety rules.
The central flow is:
client command
-> leader log append
-> follower replication
-> majority acknowledgement
-> committed log entry
-> state machine application
Raft’s safety depends on several mechanisms working together:
- Terms identify election epochs.
- One vote per term prevents multiple leaders in the same term.
- Log freshness checks prevent stale candidates from becoming leader.
- AppendEntries consistency checks repair divergent follower logs.
- Majority quorums preserve committed entries across leader changes.
- State machines apply only committed entries in log order.
The protocol is a strong fit for metadata, configuration, coordination, and control-plane systems that need consistent replicated state across a small group of trusted nodes. It is not a complete database, not a Byzantine fault tolerant protocol, and not a way to make minority partitions accept safe writes. Its main value is narrower and important: it gives a practical, understandable mechanism for making a cluster agree on one ordered history of state changes.
Leave a Comment