S3 Multi part upload
Published:
Understanding Amazon S3 Internals
Amazon S3 appears simple externally, but internally it operates as a highly scalable distributed storage system with strict durability, availability, and consistency guarantees. This post explores three core subsystems that power S3:
- Control Plane: Manages object metadata, like an index in a book.
- Data Plane: Stores the actual raw data of your objects.
- Metadata Store: A highly consistent database that powers the Control Plane.
Each subsystem has a distinct responsibility and contributes to S3’s performance and resilience. The examples below illustrate how PUT, GET, and multipart upload operations use these components.
The Core Components of S3
1. S3 Data Plane
The data plane is responsible for storing and serving the raw object bytes. It manages:
- Object data storage
- Replication across Availability Zones
- Checksumming and integrity validation
- Encryption at rest
- High-throughput upload and download handling
Key characteristics:
- Objects are stored as immutable blobs.
- Every blob is synchronously replicated across three or more AZs.
- The data plane does not store object names, metadata, or buckets; it only stores data.
- Data placement uses hashing to distribute load across thousands of nodes.
Example: Single PUT When uploading cat.jpg (10 MB):
- The client sends a PUT request.
- S3 streams the data to the data plane.
- The data plane writes an immutable blob, e.g.:
BlobID: s3data-ABCD1234 Replicas: AZ-a → node 55 AZ-b → node 13 AZ-c → node 78 - A pointer to this blob is written into the control plane. The data plane itself does not know the object is named
cat.jpg.
2. S3 Control Plane
The control plane stores and manages object metadata, including:
- Bucket and key names
- Version information
- Pointers to data-plane blobs
- ACLs, tags, storage class
- Multipart upload state
Think of the control plane as a scale-out object index. It is built on a distributed, strongly-consistent metadata service backed by consensus replication across multiple AZs. Metadata mutations (like PUT, DELETE, or CompleteMultipartUpload) are atomic operations.
Example: Single PUT For the cat.jpg uploaded earlier, the control plane creates a record linking the object’s name to its data:
ObjectRecord:
Key: "cat.jpg"
VersionId: UUID
Pointer: "s3data-ABCD1234"
Size: 10 MB
ETag: "md5"
Metadata: {...}
3. S3 Metadata Store
The metadata store is the internal, consensus-based database that powers the control plane.
- Characteristics: Strongly consistent, partitioned by bucket/key, and replicated across three or more nodes using a Paxos-like protocol for mutations.
- Stored Information: It holds structured entries for object metadata (key, version, pointer, size, etc.) and in-progress multipart uploads (UploadId, parts, state, etc.).
High-Level Architecture Diagram
To visualize how these components interact, consider this high-level diagram:
S3 Multipart Upload: A Deep Dive
Why Use Multipart Upload?
Now that we understand the core components, let’s address a fundamental question: why use multipart upload? For small files, a single PUT request is simple and efficient. However, as file sizes grow into gigabytes or terabytes, this approach becomes impractical due to:
- Network Instability: A dropped connection forces you to restart the entire upload from the beginning.
- Lack of Parallelism: You are limited to the speed of a single data stream.
- Inability to Pause/Resume: Large uploads cannot be paused and resumed later.
Multipart upload solves these problems by breaking a large object into smaller, manageable chunks that can be uploaded independently and in parallel, using the S3 architecture we just described.
Step 1: Upload Initialization
The client initiates the upload: POST /my-bucket/my-object?uploads. S3 responds with a unique UploadId for the transaction.
- Control Plane: Allocates metadata for the upload state machine (UploadId, key, permissions, etc.).
- Data Plane: No storage is allocated yet. No object is created.
Step 2: Uploading Parts
The client uploads each part (5MB–5GB) independently: PUT /bucket/key?partNumber=N&uploadId=XYZ.
What happens inside S3 when a part arrives:
- Request Routing: The request lands on an S3 front-end, which authenticates it and parses the UploadId.
- Metadata Validation: The front-end consults the metadata service to confirm the upload is valid.
- Data Storage: The part is streamed to the data plane, where it is stored as an independent internal object (e.g.,
uploadId/partNumber/randomSuffix) and synchronously replicated across multiple AZs for durability. - Metadata Update: After the part is durably stored, the control plane updates the multipart state machine with the part’s number, ETag, size, and an internal location pointer. As each part is successfully stored and replicated, the control plane updates its internal state machine to track the part’s metadata. For a concrete look at how the
MultipartUploadmetadata object evolves with each new part, see the detailed 20MB example section below.
Step 3: Parallelism
Because each part is an independent object in the data plane, uploads can happen in parallel. Different parts may land on different nodes, disks, or even AZs. This lack of locking is a core reason S3 can scale to millions of uploads per second.
Step 4: Completing the Multipart Upload
The client sends a final request listing all part numbers and their ETags. This triggers the “commit object” transaction.
The Commit Process:
- Validate Parts List: The control plane validates that all parts are present and their ETags match.
- Construct Manifest: S3 builds a manifest file. This is a metadata-only document that maps the logical object offsets to the physical locations of each part in the data plane. S3 does not physically concatenate the parts.
- Atomic Pointer Swap: In a single, atomic operation, the control plane points the object key (e.g.,
photo.jpg) to the newly created manifest. Before this step, the object does not exist. After this step, it exists as a complete, readable object. - Cleanup: The multipart upload is marked as “completed,” and the temporary part objects are scheduled for garbage collection.
What if something goes wrong? If an upload is cancelled, the client can issue an AbortMultipartUpload request. S3 then marks the transaction as aborted and adds the orphaned part-blobs to the garbage collection queue, ensuring no storage is leaked.
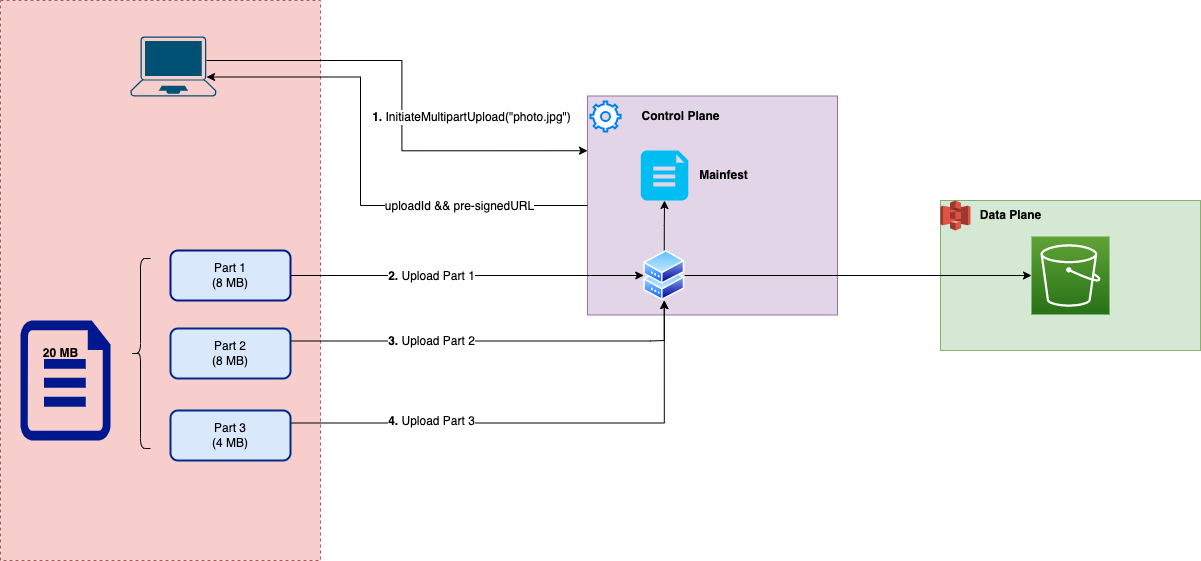
Example of a 20MB Multipart Upload
Step 1: Initiate
InitiateMultipartUpload("photo.jpg") creates an UploadId and an empty set of parts in the control plane. The object does not exist yet.
Step 2: Upload Parts (one by one)
1. Upload Part 1 (partNumber = 1) S3 stores the actual data on a storage node (say node X) as a blob:
BlobId = blob-x-7781
Size = 8MB
ETag = "md5_1"
The control plane then updates the multipart metadata:
MultipartUpload:
UploadId = A1B2C3
Key = "photo.jpg"
Parts = {
1: { pointer = blob-x-7781, size = 8MB, etag = "md5_1" }
}
State = UPLOADING
There is still no manifest yet. Just part pointers stored in the metadata of an in-progress upload.
2. Upload Part 2 (partNumber = 2) This part is stored somewhere else (e.g., node Y):
BlobId = blob-y-3290
Size = 8MB
ETag = "md5_2"
The metadata becomes:
Parts = {
1: { ptr=blob-x-7781, size=8MB, etag="md5_1" },
2: { ptr=blob-y-3290, size=8MB, etag="md5_2" }
}
3. Upload Part 3 (partNumber = 3)
BlobId = blob-z-5521
Size = 4MB
ETag = "md5_3"
The final metadata becomes:
Parts = {
1: {...},
2: {...},
3: {...}
}
Still no manifest exists, and the object still does not exist in the bucket.
Step 3: Complete
The client calls CompleteMultipartUpload with the list of parts.
The Manifest and Atomic Swap
- Manifest Creation: S3 builds a manifest, which is a small metadata document.
Manifest M123: ObjectSize = 20MB Parts = [ { offset: 0MB, pointer: blob-for-part-1, length: 8MB }, { offset: 8MB, pointer: blob-for-part-2, length: 8MB }, { offset: 16MB, pointer: blob-for-part-3, length: 4MB } ]Think of this as:
[ Manifest M123 ] --> [ Part 1 Blob ] → [ Part 2 Blob ] → [ Part 3 Blob ]This manifest is just a metadata document, a few kilobytes in size.
Before Atomic Pointer Swap
At this point:
- Multipart metadata exists
- Manifest exists
- Object does not exist in the bucket
Bucket["photo.jpg"] = <null>Nothing is visible. The manifest is built but not active.
Atomic Pointer Swap
S3 does the following in ONE atomic metadata operation:
Bucket["photo.jpg"]
← pointer to Manifest M123
This replaces the “no object” state with a new object that points to the manifest. This is the pointer swap:
(old pointer)
photo.jpg → null
|
atomic swap |
v
(new pointer)
photo.jpg → manifest M123 → [blob-x-7781, blob-y-3290, blob-z-5521]
This operation is a tiny row update in the metadata database. No data is moved. No blobs are copied. S3 only swaps a metadata pointer.
Why is the Commit Step Atomic?
This single pointer update is executed through S3’s consensus-backed metadata store, which guarantees linearizable transactions. This means either the object photo.jpg exists fully, or it does not exist at all. No partial state is ever exposed to the user.
How S3 Reads the Object: The GET Flow
- The client sends a
GETrequest forphoto.jpg. - The control plane looks up the object record and finds that it points to a manifest.
- S3 reads the manifest and streams the data-plane blobs in the correct order (part 1, then part 2, then part 3) to the client. The client receives a continuous byte stream, unaware of the underlying part structure.
Key Benefits of the Multipart Architecture
This design of separating metadata (manifest) from data (part-blobs) provides several key advantages:
- Resilience: If a part fails to upload, you only need to retry that single part.
- Parallelism: Multiple parts can be uploaded simultaneously, dramatically increasing throughput.
- Efficiency: The final object is created by writing a small manifest file, an operation that is extremely fast and atomic.
- Durability: Each part is replicated and stored durably as soon as it’s uploaded.
Final Upload Flow Summary
INIT MULTIPART
↓ (creates state machine in Control Plane)
UPLOAD PART 1 → stored independently in Data Plane (replicated)
UPLOAD PART 2 → stored independently in Data Plane (replicated)
...
UPLOAD PART N → stored independently in Data Plane (replicated)
↓
COMPLETE UPLOAD → manifest written & pointer swapped in Control Plane → object becomes visible
↓
cleanup of temporary part objects
Leave a Comment