Inside Redis Cluster: Slots, Gossip, Replication, and Failover
Published:
1. Introduction
Start With One Redis Node
Redis begins as a simple system to reason about: a client sends a command, a single Redis server executes it against local data, and the response comes back over the same connection. For many workloads, that model is why Redis is widely used. The operational surface is small, the latency profile is predictable, and the execution model is easy to understand.
That single-node mental model is important because Redis Cluster does not replace it. Each node in a Redis Cluster is still a Redis server executing commands against local data structures. Cluster mode adds the machinery required to spread data and traffic across multiple Redis servers while preserving the low-latency behavior that made the single-node system useful.
Conceptually, Redis Cluster is not one large Redis process. It is a group of Redis servers that coordinate which server is responsible for which keys.
The Moment One Node Is Not Enough
The model starts to break when one Redis node is no longer the right unit of scale. Memory pressure may exceed what a single machine should hold. CPU or network throughput may become concentrated on one process. Availability requirements may make maintenance windows and node failures unacceptable. Tenant growth may create uneven access patterns that cannot be solved by buying a larger instance.
At that point, the central question is no longer whether Redis can execute GET user:42 quickly. The central question is: which Redis server should receive GET user:42, and how does every client keep answering that question correctly as the system changes?
That question sits at the intersection of partitioning, routing, replication, failure detection, and operations. It is where caching becomes a distributed systems problem rather than just a performance optimization.
Once the cache crosses the boundary from one node to many, every operation carries implicit distributed-systems context:
- Which node owns this key?
- Is the owner healthy?
- Is there a replica that can take over?
- Does the client have a current view of ownership?
- What happens to in-flight requests while ownership changes?
These questions are the core subject of Redis Cluster.
Caches Are Not Databases
Databases and caches sit in different positions in a system.
A database is usually the source of truth. It is expected to preserve data, recover it after failures, and coordinate writes carefully. Because of that, databases often pay higher coordination costs.
A cache is different. Most cached data can be rebuilt from another system. If a cache entry disappears, the application can usually fetch it again from the database or service behind it. That gives a cache more freedom: it can prefer lower latency, simpler failover, and higher availability over strong consistency.
That does not make caches easy to operate. A cache may not be the source of truth, but it is often on the request path. If it becomes slow, overloaded, stale in the wrong way, or unavailable during a traffic spike, the user-facing system still suffers.
Where Scale Hurts
Capacity Stops Being One-Dimensional
The first scaling limit is usually capacity, but capacity is not just memory.
Memory is the obvious constraint: a cache can only hold as much working set as the node can fit comfortably in RAM. Once the working set grows beyond that, eviction pressure rises and the cache becomes less useful.
CPU and network are easier to underestimate. Redis command execution is fast, but every command still consumes event-loop time, parsing work, serialization work, and network bandwidth. A node can become saturated even when the data still fits in memory.
This is usually the first reason teams move from one Redis node to many: not because Redis changed, but because the workload no longer fits cleanly on one machine.
Tail Latency Becomes the Real Latency
Average latency can look healthy while users still see slow requests.
The reason is fanout. If one user request performs one cache lookup, an occasional slow lookup may not dominate the system. But if one user request performs 20 cache lookups, the request is only as fast as the slowest lookup in that group.
This is why distributed caches care so much about avoiding extra hops. A retry, a redirect, a stale routing decision, or one overloaded node may add only a few milliseconds. But when that happens across many lookups and many clients, those small delays become the slow requests users actually notice.
Hot Keys Break Average-Based Thinking
Distributing keys does not automatically distribute load.
Hashing can spread the keyspace, but it cannot make demand uniform. A celebrity profile, a flash-sale inventory record, a feature flag read by every service instance, or a dominant tenant’s session prefix can concentrate traffic on a small part of the cluster.
For example, a feature flag called checkout:new-flow may be read by every application server on nearly every checkout request. The keyspace may be evenly distributed, but that one key can still drive a disproportionate amount of traffic to one Redis node.
The operational symptom is often misleading: average cluster utilization looks healthy, while one node consumes disproportionate CPU, saturates network, or accumulates command latency. In distributed caches, averages often hide the failure.
Locality Starts to Matter
A cache hit is not only about whether the value exists. It also matters where the hit happens.
If related keys are scattered poorly, if clients route through an extra hop, or if a resharding event moves hot data at the wrong time, the system may preserve its overall hit rate while still degrading application latency.
For example, a checkout path may read a cart, user profile, pricing state, and inventory markers in one request. If those lookups are consistently routed directly to the right nodes, the path stays predictable. If clients have stale routing information and some of those reads require redirects, the cache may continue returning hits while the request path becomes slower.
This is why distributed caches care so much about deterministic routing and small routing metadata. The common path should be direct: compute the destination, send one request, receive one response.
Availability Becomes a Routing Problem
Once data is spread across nodes, failure handling is no longer just about restarting a process.
If a node disappears, the system needs to decide whether it is truly unavailable, which replacement can serve its keys, how clients learn about the change, and what happens to writes that were not replicated yet. Replicas help, but they introduce their own questions: how far behind is a replica, when is it safe to promote, and how quickly should the cluster converge?
For example, if the node serving shopping-cart keys fails during peak traffic, the application cannot simply wait for an operator to move traffic manually. The cache layer needs a way to promote another node, update ownership, and get clients sending requests to the new destination quickly enough that the failure does not become a full application outage.
Operational consequence: cache incidents often look like partial failures: only one shard, slot range, tenant, or hot key is unhealthy, while aggregate dashboards make the cluster appear underutilized.
The Redis Design Tradeoff
Redis is widely used because it makes a specific design tradeoff: for many request-path workloads, predictable low latency and operational simplicity matter more than strong consistency.
That tradeoff fits caching especially well. The database remains the source of truth. Redis absorbs the high-volume reads, counters, sessions, queues, coordination primitives, and short-lived state that would otherwise put pressure on slower systems. In that role, Redis does not need to make every operation globally ordered. It needs to be fast, predictable, and recoverable enough for the application using it.
Redis Cluster carries that same tradeoff into a multi-node system. It spreads keys across multiple masters, keeps replicas for failure recovery, and lets clients route directly to the node responsible for a key. The common path stays short: compute where the key should go, send the command there, get a response.
The important design choice is what Redis Cluster does not add. It does not put ZooKeeper, etcd, or a Raft group in front of every ownership decision. A stronger coordinator could provide stricter metadata ordering, but it would also add another system to deploy, operate, secure, monitor, and keep healthy.
Redis Cluster chooses a lighter model. Redis nodes coordinate with each other. Clients cache routing information. Redirects repair stale client views. Replicas can be promoted when masters fail. The system has enough coordination to stay available through common failures, but it avoids turning the cache into a consensus database.
That is the core tradeoff behind the rest of the architecture: keep the normal request path direct, and handle topology change as an exceptional path. The physical shape of a Redis Cluster is the starting point for understanding how that tradeoff is implemented.
2. Redis Cluster Architecture
The Three Building Blocks
Redis Cluster answers the multi-node problem with three ideas:
- A master is a Redis node that accepts writes for some keys.
- A replica is a Redis node that follows a master and can take over if that master fails.
- A routing map tells clients which master should receive a command for a given key.
Everything else in the architecture exists to keep those three facts useful under change. Redis nodes exchange topology information with each other. Failure detection determines when a master is no longer safe to treat as available. Failover promotes a replica. Client redirects repair stale routing views.
This is a useful way to read Redis Cluster: not as a collection of features, but as a system that tries to keep key ownership available and cheap to discover.
The Shape of the Cluster
Redis Cluster is built from ordinary Redis nodes arranged into master-replica groups. Masters serve client writes. Replicas copy data from masters and provide candidates for failover. The cluster’s job is to keep track of which master is responsible for which keys, and to help clients reach that master directly.
Client Traffic: The Data Plane
The first kind of traffic is application traffic. Clients send commands such as GET, SET, INCR, MGET, or Lua scripts to Redis nodes. This is the traffic users indirectly wait on, so every extra hop shows up in request latency.
In Redis Cluster, clients do not send every command to a single cluster endpoint that hides the topology. A cluster-aware client learns which Redis node should receive a key and sends the command directly there.
For example, when a checkout service reads cart:123, the ideal path is one network hop from the service to the Redis master responsible for that key. Redis Cluster is designed so a capable client can make that decision locally once it has learned the cluster layout.
Node-to-Node Traffic: The Control Plane
The second kind of traffic is coordination traffic between Redis nodes. Redis nodes need to exchange health information, topology changes, failure reports, promotion decisions, and ownership updates. This traffic does not execute application commands; it keeps the cluster’s view of itself moving toward agreement.
For example, if a master stops responding, other nodes need to exchange enough information to decide whether it has failed and which replica should take over. That coordination happens between Redis nodes rather than through every client request.
Keeping these two flows separate is central to Redis Cluster’s design. Client commands stay on the shortest possible path, while cluster coordination happens in the background between Redis nodes.
Masters, Replicas, and Failure Domains
A master is the active owner for a group of keys. It receives writes and streams those changes to its replicas. A replica is a copy that follows the master and can become the new master if the original one fails.
That placement only helps if replicas live in a different failure domain from the master they protect. If a master and its replica are on the same host, rack, or availability zone, a single infrastructure failure can remove both at once.
For example, suppose M1 runs in AZ-a. A useful replica for M1 should run in AZ-b or AZ-c. If AZ-a fails, the cluster still has a copy of M1’s data elsewhere and can promote that replica. If both M1 and its replica were in AZ-a, replication would exist on paper but would not protect the system from the failure that matters.
The exact layout depends on the environment, but the principle is stable: masters serve traffic, replicas provide recovery options, and placement determines whether those recovery options survive real infrastructure failures.
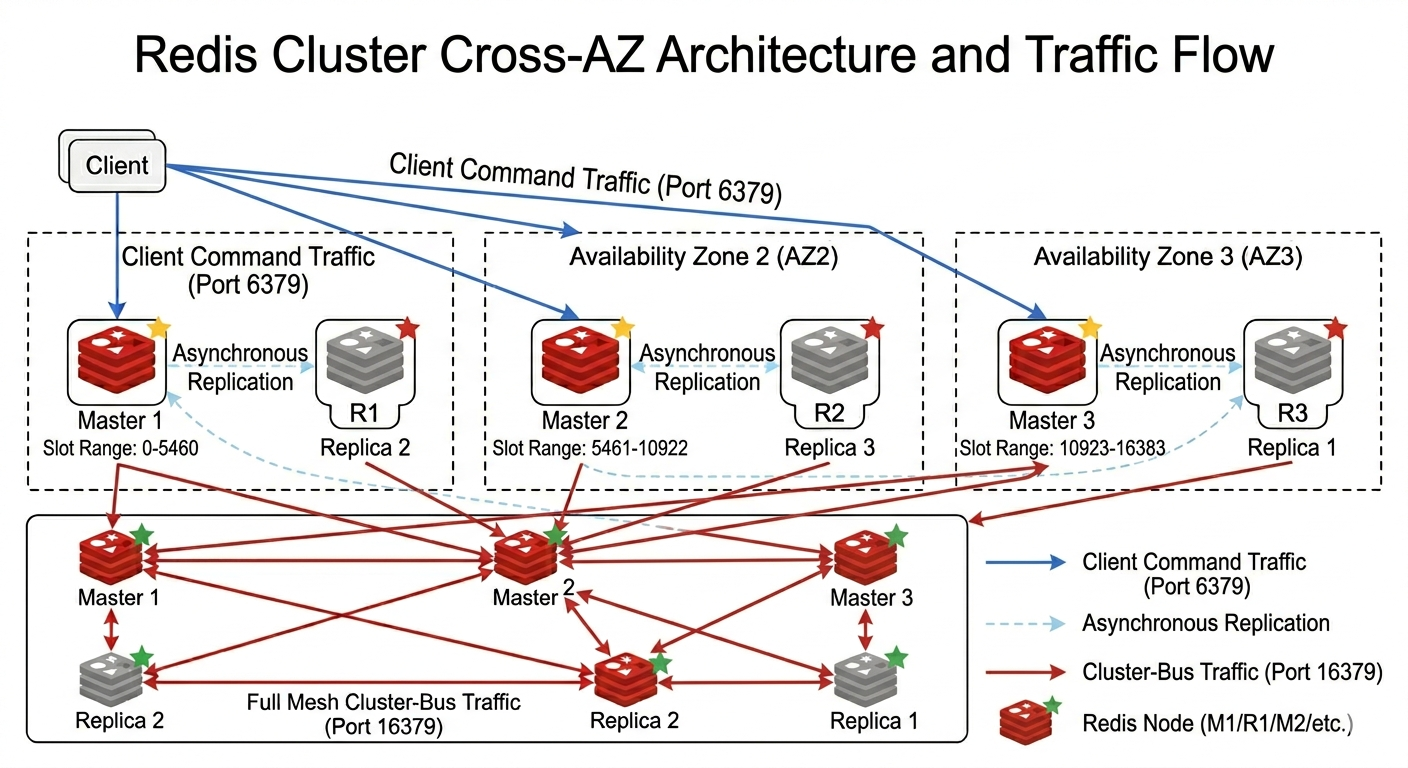
The Cluster Bus
Redis nodes need their own communication channel that is separate from application commands. That channel is the cluster bus.
Client traffic answers questions like: “What is the value of cart:123?” Cluster-bus traffic answers different questions: “Which nodes are alive?”, “Which replicas follow which masters?”, “Has a master stopped responding?”, and “Has the cluster topology changed?”
For example, suppose M1 stops responding. The application clients may only see timeouts. The Redis nodes need to do something more coordinated: exchange observations, decide whether the failure is real, choose an eligible replica, and help the cluster converge on the new topology. That coordination happens over the cluster bus.
Redis Cluster uses a full mesh for this communication. Each node maintains cluster-bus connections to the other nodes, so topology information can spread without a separate coordination service sitting in the middle.
This is the architectural role of the cluster bus: it is Redis Cluster’s built-in coordination fabric. Instead of asking an external metadata service for every topology decision, Redis nodes exchange enough information among themselves to keep the cluster moving toward a shared view.
Application commands do not use the cluster bus, but the state propagated over it is visible through Redis Cluster inspection commands:
redis-cli CLUSTER NODES
redis-cli CLUSTER INFO
CLUSTER NODES shows one node’s current view of cluster membership: node IDs, addresses, roles, link state, and ownership metadata. CLUSTER INFO summarizes cluster health. In a decentralized system, these commands are best read as inspecting one Redis node’s current view of the cluster.
Why There Is No External Coordinator
Redis Cluster could have been designed around an external coordinator such as ZooKeeper, etcd, or a dedicated Raft group. That coordinator would keep the authoritative view of the cluster: which nodes exist, which nodes are healthy, and which node should serve each part of the data.
That design has real advantages. A consensus-backed coordinator can provide a cleaner serialization point for topology changes. There is one place to decide what the latest cluster state is.
But it also changes the system being operated. Now the cache depends on another distributed system. That coordinator must be deployed, secured, monitored, upgraded, quorum-managed, and placed correctly across failure domains. If it becomes slow or unavailable, the cache’s control plane is affected too.
Redis Cluster makes a different tradeoff. It lets Redis nodes coordinate with each other directly. Failure observations start locally and spread through the cluster. Nodes eventually converge on topology changes. Ordinary commands do not wait for a central consensus round before they can execute.
For example, during a failover, a coordinator-based design might require nodes to write the new owner into a consensus-backed metadata store before clients treat the topology as updated. Redis Cluster instead lets Redis nodes exchange failure reports and converge on the promotion themselves. That is less strict, but it removes a separate metadata system from the operational path.
For a cache, that tradeoff is often attractive. The system gives up some metadata strictness, but it keeps the operational model smaller and the common request path shorter.
Tradeoff: Redis avoids operating a separate consensus system, but the cluster must tolerate temporary disagreement and repair stale views through redirects, epochs, and gossip convergence.
What Decentralization Costs
Decentralization removes a coordinator, but it does not remove coordination. It moves coordination into the Redis nodes and into cluster-aware clients.
The first cost is temporary disagreement. During a failover or resharding event, one client may still believe a key belongs to the old master while another client has already learned the new owner. Some Redis nodes may observe a failure earlier than others.
The second cost is redirects. A client can send a command to a node that is no longer responsible for that key. Redis handles this by returning a redirect response, and the client is expected to update its view and retry. Redirects are not an edge case in Redis Cluster; they are part of the topology-change protocol.
The third cost is operational reasoning. Operators need to understand replica lag, failure timeouts, ownership changes, migration state, and client refresh behavior. The cluster is designed to converge, but convergence is still a process that takes time and depends on clients behaving correctly.
Decentralization removes one operational dependency, but it exposes another: the Redis cluster itself must spread state, correct stale views, and converge after change.
Scaling the Full Mesh
A full mesh is easy to understand at small scale. In a six-node cluster, each node can maintain direct cluster-bus connections to the other five nodes. Failure observations and topology updates have many paths to spread.
The tradeoff appears as the node count grows. A 10-node cluster has far fewer node-to-node relationships than a 100-node cluster. Each node has more peers to track, more gossip state to process, and more cluster-bus traffic to maintain.
This is why Redis Cluster is usually most comfortable at tens or low hundreds of nodes, not thousands of nodes in one logical cluster. At very large scale, teams often compose multiple Redis clusters behind application-level routing, tenancy boundaries, or a proxy layer.
That limit is part of the design. Redis Cluster favors a cluster size where the system remains understandable, the data path stays direct, and node-to-node coordination remains manageable. To understand why the data path can stay direct, the next piece is the routing abstraction: hash slots.
3. Hash Slots and Request Routing
Why Routing Exists
The moment a cache is split across multiple masters, the system needs a rule for ownership. Every key must have a home. If user:123 lives on one master and cart:456 lives on another, clients need a way to find the right destination before sending a command.
This routing decision sits on the hot path. It cannot require a broadcast. It cannot require every request to consult a coordinator. It cannot be so dynamic that clients constantly throw away their routing state. The common case needs to be local and deterministic: given a key, compute where the request should go.
At the same time, the rule cannot be rigid. Redis Cluster must support adding masters, removing failed masters, promoting replicas, and moving data during rebalancing. A routing scheme that is fast but impossible to change is not useful operationally.
Redis hash slots are the compromise: a fixed logical namespace between keys and masters. Clients compute key -> slot; the cluster tells clients slot -> master.
The ideal steady-state path is simple:
client computes destination -> client sends command directly to the right master
No coordinator lookup. No proxy hop. No broadcast. One key should lead to one owner.
Why Simple Partitioning Breaks
The simplest routing idea is to hash the key directly to a node:
node = hash(key) % number_of_nodes
This works only while the node count stays fixed. If the cluster grows from 3 masters to 4 masters, number_of_nodes changes. Many keys now map to different destinations even though nothing about those keys changed.
For example, with three masters:
hash(user:123) % 3 = 0 -> M1
hash(cart:456) % 3 = 1 -> M2
hash(product:999) % 3 = 2 -> M3
After adding a fourth master:
hash(user:123) % 4 = 2 -> M3
hash(cart:456) % 4 = 0 -> M1
hash(product:999) % 4 = 1 -> M2
The keys did not change, but their destinations did. In a large cache, adding one node can cause a large fraction of keys to be looked up on the wrong machines.
That is operationally painful. Adding capacity can turn into a large cache invalidation event because clients start looking for many keys on different nodes. The origin database or backend service may suddenly receive a wave of misses while the cache warms back up.
Another option is a centralized routing table. A coordinator could store a map like:
keys A-M -> node 1
keys N-Z -> node 2
That gives more control, but it creates a new dependency. Either every request needs to consult the coordinator, which adds latency and availability risk, or clients cache the routing table, which means the system still needs a way to correct stale client views.
Static ranges over key names have a different problem: real workloads are not evenly distributed by names. A large tenant, a hot product, or a popular feature flag can concentrate traffic in one range. The partitioning scheme may look clean while production load remains uneven.
Consistent Hashing Gets Closer
Consistent hashing improves the direct modulo approach by changing the unit of movement.
Instead of computing hash(key) % number_of_nodes, consistent hashing places both keys and nodes on a logical ring. A key belongs to the first node encountered while walking around the ring.
The advantage is that adding a node does not reshuffle the whole cache. Only the keys that now fall between the new node and its predecessor move. Virtual nodes can smooth distribution further by giving each physical node many positions on the ring.
This is much better than modulo hashing, and many distributed caches use consistent hashing or a variant of it. Redis Cluster takes a related but more explicit path: it introduces a fixed logical namespace between keys and masters. Redis calls that namespace hash slots.
Redis Hash Slots
Redis Cluster introduces hash slots as a fixed routing namespace between keys and masters.
A slot is not a key. It is not a storage partition with a fixed capacity. It is a routing bucket. Redis Cluster has 16,384 slots, not a 16,384-key limit.
many keys -> one slot -> one master
Many independent Redis keys can map to the same slot:
user:123 -> slot 12893
cart:456 -> slot 12893
session:abc -> slot 12893
Those keys remain separate Redis keys. They simply share the same routing bucket, which means Redis Cluster sends them to the same master. The practical key limit comes from memory, object sizes, CPU, network throughput, eviction policy, and operational constraints.
Hash slots are metadata. A Redis node does not create 16,384 independent dictionaries, files, memory arenas, or local databases. Once a command reaches the right master, the key is stored in that node’s normal in-memory data structures. The slot tells the cluster where the key belongs; it does not define a physical storage partition inside the node.
The reason slots exist is indirection. Redis does not map keys directly to masters. It maps each key to a slot, and then maps each slot to a master:
key -> hash slot -> owning master
The key-to-slot calculation does not change when masters are added, removed, or replaced. What can change is slot ownership.
user:123 -> slot 12893 -> master M3
cart:9 -> slot 4211 -> master M1
If the cluster later rebalances, slot 12893 can move from M3 to M4. user:123 still hashes to slot 12893; only the slot owner changes.
Before rebalancing:
slot 12893 -> M3
user:123 -> slot 12893 -> M3
After rebalancing:
slot 12893 -> M4
user:123 -> slot 12893 -> M4
The key did not need a new hash function, and the client did not need a per-key routing table. Only the slot owner changed.
That indirection is the core design. Redis gets deterministic client-side routing without permanently tying each key to a physical node.
Each slot has an owner. In a simple three-master cluster, ownership may look like this:
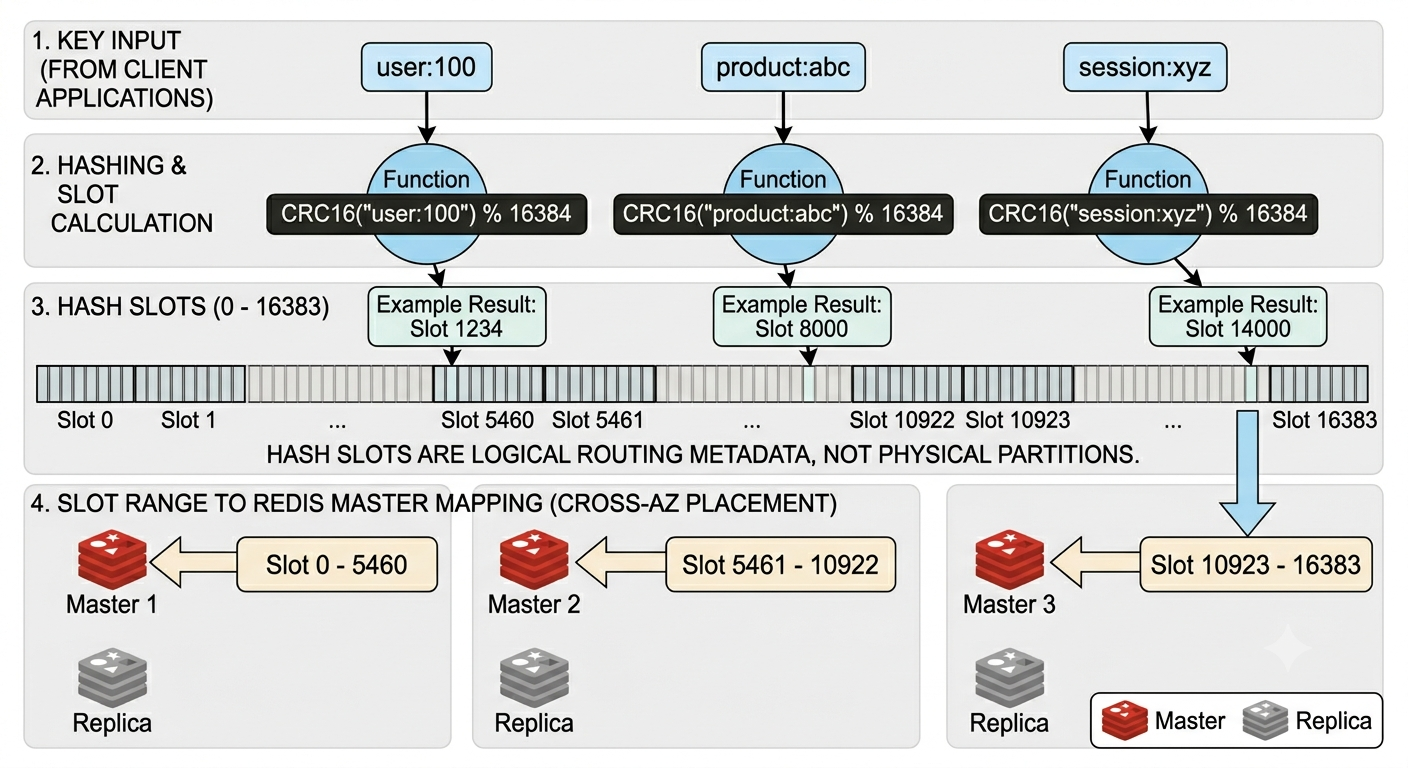
Clients do not need to ask the cluster about every key. They need a slot map: which master owns which slot or slot range. That map is small enough to cache in process and cheap enough to refresh when topology changes.
How Redis Computes a Slot
Redis computes a slot in two steps:
hash = CRC16(key)
slot = hash % 16384
CRC16 turns the key into a deterministic integer. The modulo operation compresses that integer into Redis Cluster’s fixed slot range: 0 through 16383.
For example:
redis-cli CLUSTER KEYSLOT user:123
Example output:
(integer) 12893
The exact number is less important than the property: every cluster-aware client computes the same slot for user:123. No network lookup is required to answer key -> slot.
Most keys use the full key string for this calculation. Redis also provides one controlled escape hatch: hash tags. If a key contains a substring inside {...}, Redis hashes only that substring:
cart:{user:42} -> hashes user:42
profile:{user:42} -> hashes user:42
The result is that both keys land in the same slot:
redis-cli CLUSTER KEYSLOT cart:{user:42}
redis-cli CLUSTER KEYSLOT profile:{user:42}
Example output:
(integer) 15880
(integer) 15880
The values match because Redis hashes only user:42, not the full key names. This matters for multi-key operations that require keys to live together. The tradeoff is that overusing the same tag can create hotspots.
Inspecting the Slot Map
The slot map is not only an internal idea. Redis exposes it through cluster commands, which are useful for debugging routing, failover, and resharding behavior.
# Show slot ranges, masters, and replicas
redis-cli -c CLUSTER SLOTS
# Show node IDs, addresses, roles, link state, epochs, and slot ownership
redis-cli CLUSTER NODES
CLUSTER SLOTS is the client-friendly view. It groups slot ranges with the master and replica addresses clients need for routing:
1) 1) (integer) 0
2) (integer) 5460
3) 1) "10.0.1.10"
2) (integer) 6379
3) "node-id-m1"
4) 1) "10.0.2.11"
2) (integer) 6379
3) "node-id-r1"
2) 1) (integer) 5461
2) (integer) 10922
3) 1) "10.0.2.10"
2) (integer) 6379
3) "node-id-m2"
CLUSTER NODES is the node-centric view. It shows node IDs, addresses, roles, link state, configuration epochs, and slot ownership:
07c37... 10.0.1.10:6379@16379 master - 0 0 1 connected 0-5460
3c3a0... 10.0.2.10:6379@16379 master - 0 0 2 connected 5461-10922
fbd12... 10.0.3.10:6379@16379 master - 0 0 3 connected 10923-16383
8a81f... 10.0.2.11:6379@16379 slave 07c37... 0 0 1 connected
These commands expose the same basic information a cluster-aware client needs: slot ranges and the Redis node addresses that own them. Operators inspect this data manually; clients fetch and cache it automatically.
How Clients Use the Slot Map
Redis Cluster does not hide routing behind a single proxy. A cluster-aware client keeps a local copy of the slot map and uses it before sending commands.
That means the client does two jobs:
- It computes the slot for a key.
- It uses its cached slot map to choose the Redis node for that slot.
The request flow looks like this:
- The client opens a connection to any reachable cluster node.
- It fetches the slot map with
CLUSTER SLOTSor an equivalent command. - It builds an in-memory map from slot ranges to node addresses.
- For each command, it computes
CRC16(key) % 16384. - It sends the command directly to the node that owns the slot.
- If the node replies with a redirect, the client updates its topology view and retries according to the redirect type.
For GET user:123, the steady-state path is:
compute slot for user:123 -> find owner in local slot map -> send GET to owner
For example, suppose the client has cached this slot range:
slots 10923-16383 -> M3 at 10.0.3.10:6379
If user:123 hashes to slot 12893, the client can route directly:
GET user:123 -> M3 at 10.0.3.10:6379
No cluster-wide lookup is needed for that request.
That is the latency payoff. The common path is a local calculation plus one network hop.
When the Slot Map Is Stale
A cached slot map is what makes Redis Cluster fast in the common case. But cached metadata has one unavoidable problem: it can become stale.
A master can fail and be replaced by a replica. A slot can move during rebalancing. A client may still believe slot 12893 belongs to M3 even though the cluster has moved it to M4.
Redis Cluster needs to correct that client without forcing every request through a central coordinator. It does this with redirect responses.
There are two redirect cases:
MOVED: the slot has a new permanent owner.ASK: the slot is temporarily in transition.
MOVED: Permanent Ownership Change
MOVED means the receiving Redis node is not the owner for that slot. Instead of executing the command, it returns a redirect that tells the client where the slot currently lives.
-MOVED 12893 10.0.3.10:6379
In plain language: “slot 12893 is owned by the Redis node at 10.0.3.10:6379; update the slot map and retry there.”
ASK: Temporary Migration Redirect
ASK means the slot is in transition. During migration, some keys for a slot may still live on the source while others have already moved to the target.
-ASK 12893 10.0.3.10:6379
The client should send ASKING to the target and retry the command there, but it should not permanently rewrite the slot map just because it received ASK.
The short version is: MOVED updates the routing table; ASK redirects one command during migration.
Moving Slots Without Stopping the Cluster
Slots are useful because they give Redis Cluster a movable unit of ownership.
When a new master is added, the cluster does not need to invent a new hash function or remap every key directly. It can move some slots from existing masters to the new master.
For example, suppose M1 owns slots 0-5460 and the cluster adds a new master, M4. Redis can move a subset of slots from M1 to M4:
Before:
slots 0-5460 -> M1
After:
slots 0-3999 -> M1
slots 4000-5460 -> M4
A key that hashes to slot 4200 still hashes to slot 4200. What changes is the owner of slot 4200.
Moving a slot has two parts:
- The cluster changes ownership metadata: this slot should belong to the target master.
- The actual keys that hash to that slot must be migrated from the old master to the new master.
The second part is the expensive one. Keys are real data: memory, network bytes, allocator work, and event-loop time.
During migration, the source may still hold some keys while the target has already received others. That is why ASK exists. It lets Redis redirect individual commands during the temporary migration window without telling the client to permanently change its slot map too early.
Operationally, resharding is not free. Moving a cold slot may be cheap. Moving a slot with large values or hot keys can consume CPU, network, allocator work, and event-loop time on both the source and the target.
Operational consequence: a slot is the unit of ownership, but the cost of moving it is determined by the keys and traffic inside it.
Why 16,384 Slots
The number of slots controls the tradeoff between rebalance granularity and metadata overhead.
If Redis had very few slots, each slot would represent a large portion of the keyspace. Moving one slot during rebalancing could move too much data and too much traffic at once.
If Redis had millions of slots, rebalancing could be very fine-grained, but every node and every cluster-aware client would need to carry much larger routing metadata. Gossip messages, topology updates, and client slot maps would all become heavier.
16,384 is the middle ground. It gives Redis enough slots that ownership can be spread and rebalanced in reasonably small units, while keeping the slot map compact enough for clients and nodes to store and update cheaply.
It also gives Redis a fixed routing universe. Clients know there are always 16,384 possible slots, and the cluster only needs to tell them who owns each one.
Why This Model Works
Redis Cluster routing works because it separates a stable calculation from changing ownership.
key -> slot stable calculation
slot -> master cluster metadata
The first step is deterministic. A client can compute the slot locally for every command.
The second step is metadata. Slot ownership can change during failover or rebalancing, and clients can refresh that metadata when needed.
This gives Redis Cluster a useful balance:
- normal requests are direct,
- topology changes do not require changing the hash function,
- rebalancing happens at slot granularity,
- clients can recover from stale views through redirects,
- the cluster avoids a coordinator on the request path.
That is the core of Redis Cluster request routing: a fixed routing namespace, movable ownership, and clients that understand both.
4. Internal Key Storage
After Routing, Redis Is Local Again
Once a command reaches the correct master, Redis Cluster mostly disappears from the hot path. The node does not perform a distributed lookup. It executes the command against local in-memory data structures, the same way a standalone Redis server would.
For example, after the client routes GET user:123 to the correct master, the server looks up user:123 locally and returns the value. The cluster decided where the command should go; the Redis node decides how to execute it.
The redisDb Dictionary
Inside a Redis node, keys are stored in a database object commonly represented by redisDb. The main key dictionary maps Redis keys to Redis objects:
+----------------------+
| redisDb |
| +------------------+ |
| | dict (hash table) | | <--- O(1) key lookup
| +------------------+ |
+----------------------+
Key: "user:123" --> redisObject (string, list, etc.)
The value is a redisObject, which may represent a string, list, hash, set, sorted set, stream, or another Redis data type. The important point is that normal command execution is a local dictionary lookup followed by data-type-specific logic.
Why Redis Does Not Store Per-Slot Dictionaries
Redis does not create one dictionary per hash slot. A node may own thousands of slots, but its keys live in the node’s normal key dictionary.
That keeps the local execution model simple. A read or write does not first descend into a per-slot storage engine. Once the command reaches the right node, Redis can use its highly optimized hash table path.
Incremental rehashing works by gradually migrating entries from an old hash table to a new one during normal operations, avoiding latency spikes.
This is also why slot movement has two different costs. Changing slot ownership is metadata. Moving the keys that belong to that slot is real work: Redis must identify keys for the slot and migrate them to the target node.
Operational Implication
The routing layer and the storage layer solve different problems.
The routing layer answers: which node should receive this command?
The storage layer answers: once the command reaches that node, how quickly can Redis find and operate on the key?
Redis Cluster keeps those concerns separate. Slots make distributed ownership manageable, while the local dictionary keeps single-node command execution fast and predictable.
5. Cluster Metadata and Node Tables
Each Node Has a Local View
Redis Cluster does not keep cluster state in one external metadata service. Each Redis node keeps its own local view of the cluster.
That local view is stored in a node table. It is the node’s working model of the system: which Redis nodes exist, which ones are masters or replicas, which masters own which slots, which nodes appear healthy, and which topology updates are newer than others.
This local view is what makes decentralized coordination possible. A node can receive a command, decide whether it owns the relevant slot, redirect the client if it does not, detect peer failures, and participate in failover decisions using the metadata it already has locally.
What the Node Table Contains
The node table contains several categories of metadata:
- Node IDs: Unique 40-character hex strings.
- Slot ownership: Which slots each node claims.
- Ping/Pong timestamps: For failure detection.
- Epochs: Logical clocks for failover elections.
- Role: Master or replica.
- Fail state: Flags indicating suspected or confirmed failures.
- Replication metadata: Master link status, replication offsets.
These fields are not just bookkeeping. They are the inputs Redis uses to answer operational questions:
- Should this node serve the command or redirect it?
- Has a peer stopped responding long enough to be considered suspect?
- Which replica follows which master?
- Which topology update should win if two nodes report conflicting ownership?
- Is a replica eligible to be promoted?
A simplified node table might look like this:
Node ID Address Role Master Link Slots
07c37... 10.0.1.10:6379 master - connected 0-5460
3c3a0... 10.0.2.10:6379 master - connected 5461-10922
fbd12... 10.0.3.10:6379 master - connected 10923-16383
8a81f... 10.0.2.11:6379 replica 07c37... connected -
From this local table, a node can infer several things:
- slots
0-5460belong to07c37..., 8a81f...is a replica of07c37...,- all listed links are currently connected,
- a command for slot
12000should be served byfbd12...or redirected there.
Why Node IDs Matter
Redis nodes have stable IDs because addresses can change. A node may restart, move to a different IP, or be reached through a different endpoint, but the cluster still needs a stable identity for membership and replication relationships.
The node ID is that identity. It lets the cluster distinguish “this is the same Redis node at a new address” from “this is a different Redis node.”
Why Epochs Exist
In a decentralized system, two nodes may temporarily disagree about ownership or failover state. Redis uses epochs as logical clocks to order topology changes.
An epoch does not make Redis Cluster a consensus database. It gives nodes a way to compare competing claims and prefer the newer cluster configuration. This matters during failover, slot migration, and recovery from partitions.
Metadata Is Local, Not Globally Synchronous
Every node has a node table, but that does not mean every node always has the exact same table at the exact same instant. Cluster metadata spreads over the cluster bus and converges over time.
That is the central tradeoff. Redis avoids a central metadata service, but each node must maintain enough local state to make progress while the cluster converges. The next section explains how that state spreads: gossip.
6. Gossip Protocol Internals
Why Gossip Exists
Every Redis node has a local node table, but those tables do not update themselves. When a node observes a failure, learns about a new node, or sees a topology change, that information has to spread to the rest of the cluster.
Redis Cluster uses gossip for that propagation. Gossip is a practical fit for Redis because it does not require a central coordinator and it does not require every observation to be synchronously committed through a consensus log. Nodes exchange small pieces of cluster state until their local views converge.
PING and PONG Are Metadata Carriers
Redis Cluster nodes periodically send PING messages to other nodes over the cluster bus. The receiving node replies with PONG.
These messages are not only liveness checks. They also carry metadata about the sender and about other nodes the sender knows about. That is how information spreads beyond the two nodes directly communicating.
For example, when M1 pings M2, the packet can include what M1 currently believes about M3, replicas, failure flags, and topology state. M2 can merge that information into its own node table if it is newer or previously unknown.
How a Gossip Exchange Works
A gossip exchange is a small state synchronization between two Redis nodes.
At a high level, the loop looks like this:
1. Pick a peer.
2. Send a cluster-bus PING containing local cluster metadata.
3. Receive a PONG containing the peer's cluster metadata.
4. Merge newer or missing information into the local node table.
5. Repeat with other peers over time.
The payload is not a full database dump and it is not the complete keyspace. It is cluster metadata: node IDs, addresses, roles, link state, failure flags, configuration epochs, slot ownership, and selected information about other nodes.
For example:
M1 -> M2 PING:
sender: M1
known state:
M3: PFAIL according to M1
R3a: replica of M3
M4: connected
M2 -> M1 PONG:
sender: M2
known state:
M3: OK according to M2
M5: connected
R1a: replica of M1
After receiving the packet, each node compares the incoming metadata with its own node table. Some information may be ignored because it is older. Some may update timestamps. Some may add a failure report. Some may reveal a node or topology change the receiver had not yet seen.
This is why gossip can spread information beyond direct neighbors. If M1 tells M2 about a suspected failure, and M2 later talks to M4, M4 can learn about M1’s observation even if M1 and M4 did not exchange packets at that moment.
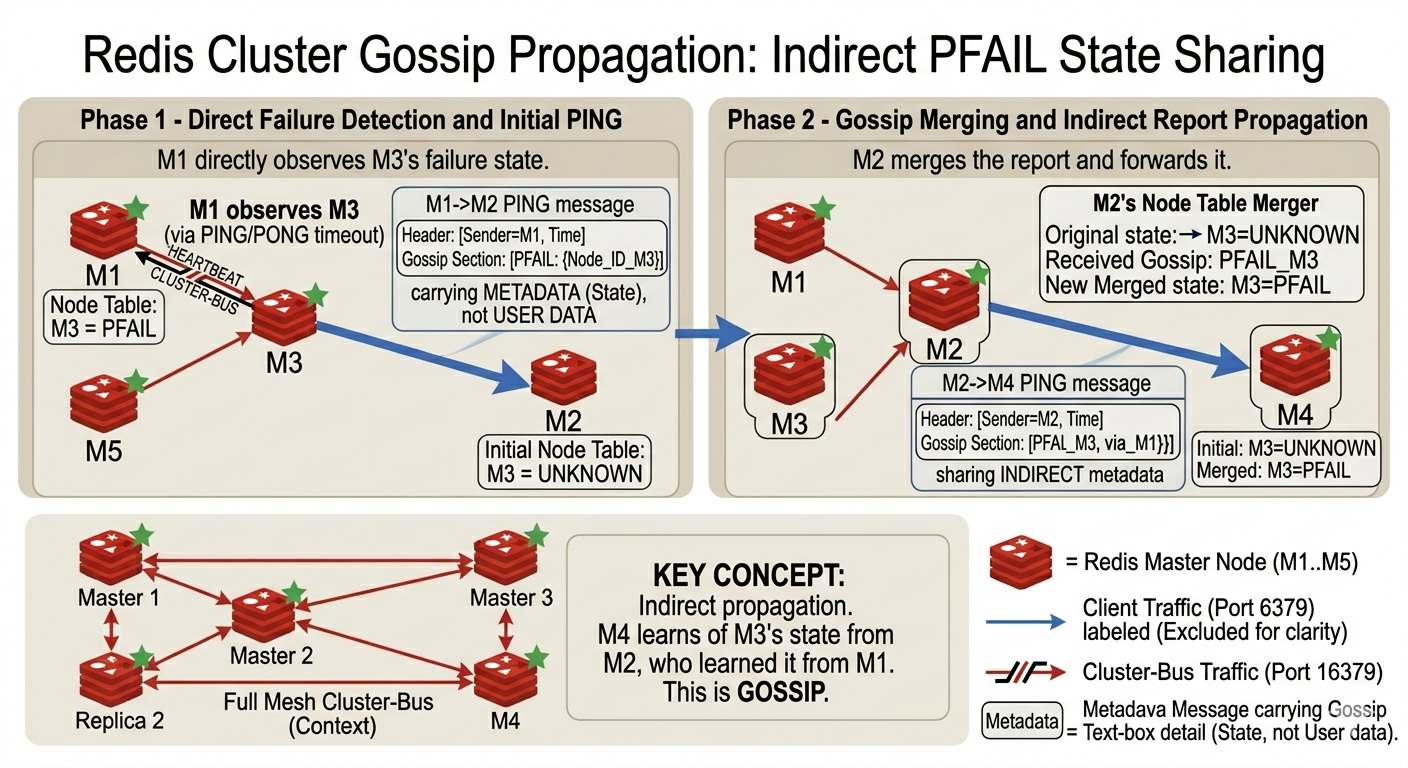
From Local Suspicion to Cluster-Wide Failure
Failure detection starts locally. If M1 stops receiving timely responses from M3, it does not immediately mean M3 is globally dead. It may be a local network issue, a transient pause, or one node’s limited view of the world.
Redis first marks the node as PFAIL: possible failure. That means one node suspects a peer is unhealthy in its own local view.
The node does not synchronously ask every other master for a vote and block waiting for responses. Instead, suspicion spreads through normal cluster-bus gossip. Other masters may independently report that they also cannot reach the same node. Redis collects these failure reports as they arrive.
If reports from a majority of masters arrive within the failure-report validity window, one of the masters can promote the state from PFAIL to FAIL in its local node table. That FAIL state is then gossiped to the rest of the cluster. At that point, the cluster treats the failure as real and failover can proceed.
If the problem is transient or local to one node, the suspicion should not become a confirmed failure. For example, if M1 cannot reach M3 but M2 and M4 can still communicate with M3, the cluster does not have majority agreement to mark M3 as FAIL. M1 may temporarily hold a PFAIL view, but no failover should occur unless the suspicion is confirmed by enough masters.
This distinction is the reason Redis has both states:
- PFAIL: local suspicion.
- FAIL: cluster-confirmed failure.
Gossip Is Convergence, Not Consensus
Gossip gives Redis Cluster eventual convergence, not instantaneous global agreement.
That distinction matters. During a failure or topology change, different nodes may briefly hold different views. One node may have already heard about a suspected failure while another has not. Gossip is the mechanism that moves the cluster toward a shared view over time.
This fits the Redis Cluster design: ordinary commands do not wait for a global consensus round, but the cluster still has a way to spread state, detect failures, and coordinate recovery.
Example: Failure Suspicion Spreading
Cluster: masters M1, M2, M3, M4, M5
Failure target: M3
Majority of masters: 3 out of 5
Time 0:
M1 sends cluster-bus PINGs as usual.
M3 does not respond to M1 within the configured timeout.
M1 marks M3 as PFAIL in M1's local node table.
Time 1:
M1 continues normal gossip with other masters.
M1 sends a cluster-bus packet to M2 that includes: "M1 sees M3 as PFAIL."
M1 later sends a packet to M5 with the same local failure report.
M1 is not asking for a synchronous vote; it is spreading its local observation.
Time 2:
M2 also fails to receive timely responses from M3.
M2 marks M3 as PFAIL in M2's local node table.
M2's node table now contains:
- M1 reports M3 as unreachable.
- M2 reports M3 as unreachable.
M2 gossips both pieces of information in later packets.
Time 3:
M4 also cannot reach M3.
M4 marks M3 as PFAIL locally and gossips that report.
M4 may have learned M1's report from M2, or directly from M1.
M4's later gossip packets include:
- M4 reports M3 as unreachable.
- any valid failure reports about M3 that M4 has already heard.
Time 4:
Failure reports continue spreading through normal gossip.
M1 receives reports from M2 and M4.
M2 may also receive reports from M1 and M4.
M4 may also receive reports from M1 and M2.
Any master that collects valid reports from a majority can mark M3 as FAIL.
In this timeline, M1 happens to collect the majority first:
- M1's own report
- M2's report
- M4's report
M1 marks M3 as FAIL in M1's local node table.
Time 5:
M1 gossips the FAIL state for M3.
Other nodes receive the FAIL state and update their own node tables.
Replicas of M3 can now participate in failover.
M1 is not special in this example. It is not the coordinator and it does not own the failure decision globally. It is simply the first master in this timeline to collect enough valid reports. If M2 or M4 had collected the majority first, either of them could have marked M3 as FAIL and gossiped that state.
The exact timing depends on node timeouts, network behavior, and cluster size. The important pattern is local suspicion first, majority-confirmed failure second, cluster-wide propagation third.
7. Replication Internals
Why Replication Exists
Replication gives Redis Cluster a recovery path when a master fails. A replica follows a master by receiving the master’s write stream and applying those writes locally. If the master becomes unavailable, one of its replicas can be promoted and take over the master’s slots.
Replication is not primarily about making every read strongly consistent. It is about keeping a recent copy of a master’s data available for failover.
The Write Path
Redis Cluster replication is asynchronous. A write is accepted by the master, applied locally, and then propagated to replicas.
For example:
1. Client sends SET cart:123 ... to master M1.
2. M1 applies the write locally.
3. M1 replies to the client.
4. M1 sends the write command to replicas R1 and R2.
5. R1 and R2 apply the write when they receive it.
The default acknowledgment is local to the master. It means M1 accepted the command and applied it to its own in-memory state. It does not mean a quorum of replicas has applied the write.
When the Master Replies
Redis Cluster does not use quorum writes by default.
For a normal write, the master replies after local execution:
client -> M1
M1 applies write locally
M1 replies to client
M1 propagates write to replicas asynchronously
That keeps write latency low because the client is not waiting for cross-node coordination. The tradeoff is a replication-lag window: a write can be acknowledged by the master before every replica has received it.
Redis provides mechanisms such as WAIT that can ask the server to wait until a specified number of replicas acknowledge receiving recent writes. That can reduce the data-loss window for selected operations, but it is not the default Redis Cluster write path and it is not the same as a consensus commit. Redis still does not turn the write into a majority-agreed database transaction.
How Writes Reach Replicas
Replicas keep long-lived replication connections to their master. The master does not open a new connection for every write.
When the master executes a write command, it appends that command to its replication stream and writes it to the connected replicas. Each replica consumes the stream in order and replays the commands locally.
Client SET cart:123
|
v
M1 applies write locally
|
+--> replication stream -> R1 applies SET cart:123
|
+--> replication stream -> R2 applies SET cart:123
Because the stream is asynchronous, replicas may be at different positions in the stream at any moment. Redis needs a way to describe that position precisely. That is what replication offsets provide.
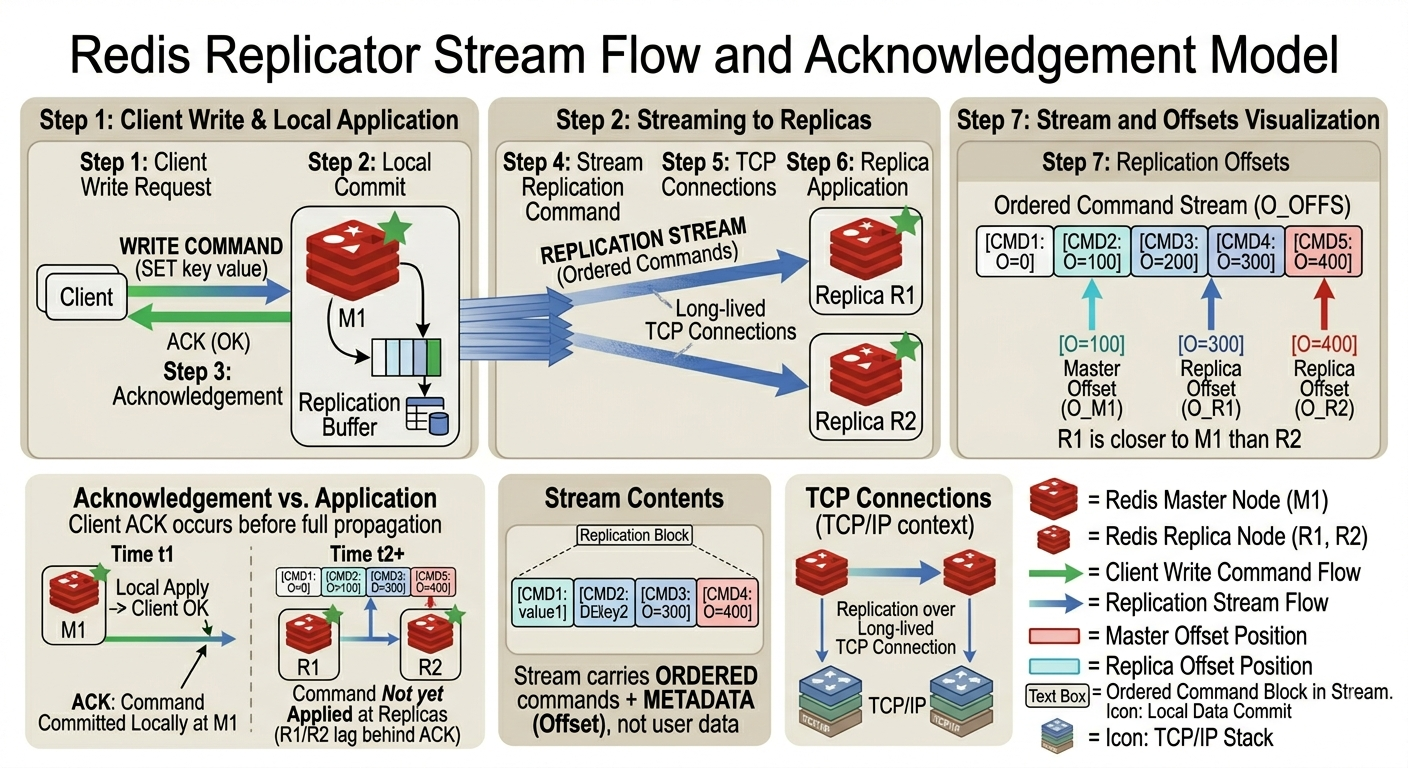
Replication Offsets
A replication offset is a position in the master’s replication stream. The master’s stream is ordered, and each replica records how far it has consumed that stream.
Conceptually:
M1 replication offset: 105000
R1 replication offset: 104980
R2 replication offset: 104200
This does not mean R1 is missing 20 keys. Offsets measure progress through the replication stream, not key count. The important signal is relative progress: R1 has consumed more of the master’s stream than R2.
If M1 fails at this moment, promoting R1 is likely to lose less recent data than promoting R2. During failover, this matters because the most up-to-date replica is usually the safest promotion candidate.
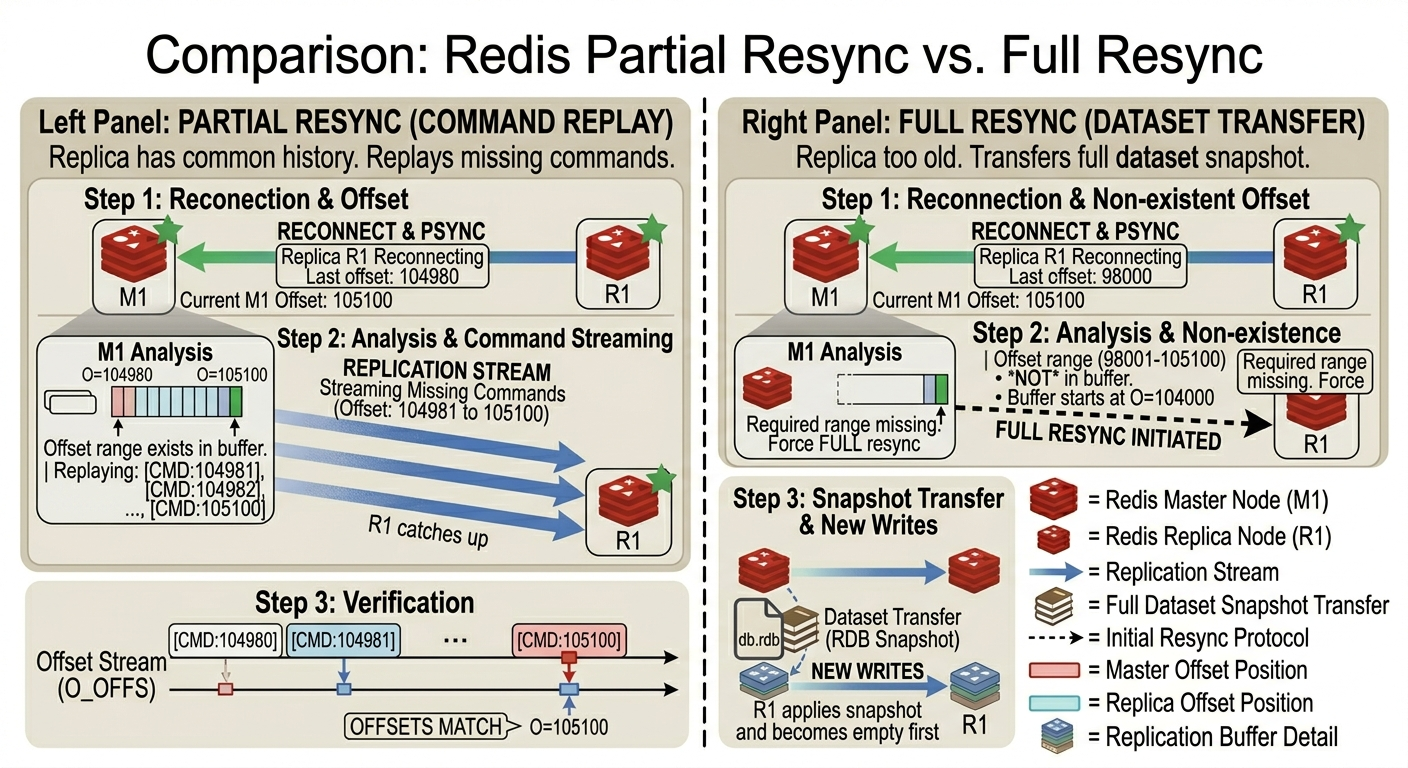
Partial Resync and the Replication Backlog
Temporary disconnects are common in real systems. A replica may lose its connection to the master for a few seconds and then reconnect.
Redis avoids a full copy whenever possible by using partial resynchronization. The master keeps a replication backlog: a fixed-size ring buffer of recent write commands. If the replica reconnects and the missing writes are still in the backlog, the master can send only the missing portion.
The backlog is a bounded replay window. It does not keep all history forever. It only keeps the most recent part of the master’s replication stream. If the replica reconnects while its missing offset range is still inside that window, partial resync works. If the master has already overwritten that part of the backlog, the replica cannot catch up incrementally.
The communication flow looks like this:
Time 0:
R1 is connected to M1.
R1 has consumed the replication stream through offset 104980.
Time 1:
The connection between R1 and M1 drops.
M1 continues accepting writes and advances to offset 105000.
M1 also keeps recent writes in its replication backlog.
Time 2:
R1 reconnects to M1.
R1 tells M1: "I was at offset 104980."
Time 3:
M1 checks its backlog.
If offsets 104981-105000 are still present, M1 can replay only that range.
Time 4:
M1 sends the missing commands to R1.
R1 applies them in order and catches up to the current stream.
The key decision happens at Time 3: can the master still replay the missing range from its backlog?
This keeps short interruptions cheap because the replica does not need to reload the full dataset. It only needs the part of the command stream it missed.
Full Resync
Full resync is the fallback when partial resync cannot work. The usual reason is that the replica is too far behind and the master’s backlog no longer contains the missing offset range.
The communication flow looks like this:
Time 0:
R1 reconnects to M1 and reports its last replication offset.
Time 1:
M1 checks the replication backlog.
The missing offset range is no longer available.
Time 2:
M1 starts a full synchronization.
It creates a snapshot of its current dataset.
Time 3:
M1 sends the snapshot to R1.
R1 loads the snapshot and replaces its local dataset with that copy.
Time 4:
While the snapshot was being created and transferred,
M1 may have accepted more writes.
After R1 loads the snapshot, M1 sends the newer writes
from the replication stream.
Time 5:
R1 applies those newer writes and resumes normal streaming replication.
Full resync is much more expensive than partial resync because it moves the dataset, not just the missing command range. It consumes CPU, memory, disk or fork overhead depending on configuration, and network bandwidth. In large Redis datasets, full resync can be operationally significant.
Inspecting Replication
Replication should be observable because replica lag directly affects failover safety.
redis-cli INFO replication
redis-cli ROLE
INFO replication is the richer operational view. On a master, it shows connected replicas, replica offsets, backlog state, and replication IDs. On a replica, it shows the upstream master, link state, and current replication offset.
ROLE is a compact sanity check. It answers whether the node is currently acting as a master or replica and what it believes its replication position is.
Useful questions during an incident:
- Is the replica link connected?
- Which replica has the highest offset?
- Is replication lag growing?
- Is the backlog available for partial resync?
- Did the replica fall back to full resync?
The Consistency Tradeoff
The replication design creates an important distinction: a write can be acknowledged by the master before it is present on any replica.
In the normal path, this is good for latency. The master does not wait for cross-node confirmation before replying to the client.
During failure, the same choice creates a data-loss window.
Time 0:
Client sends SET cart:123 to M1.
Time 1:
M1 applies the write locally and replies OK.
Time 2:
Before the write reaches R1, M1 fails.
Time 3:
R1 is promoted to master.
Result:
The new master may not contain cart:123.
From the client’s perspective, the write succeeded. From the cluster’s perspective after failover, the promoted replica never saw it.
This is not a bug in Redis Cluster; it is the consequence of asynchronous replication. Redis chooses low write latency and simpler failover over strongly consistent replication.
Operationally, this means Redis Cluster is best used where a small window of lost or stale cached state is acceptable, or where the application can reconstruct state from an authoritative system.
8. Failover Deep Dive
Failover is where Redis Cluster’s earlier mechanisms come together: gossip detects the failed master, replication determines which replica is safest to promote, epochs order the topology change, and clients repair stale routing through redirects.
Example Topology
Consider five masters and two replicas for M1:
Masters:
M1 owns slots 0-5460
M2 owns slots 5461-9000
M3 owns slots 9001-12000
M4 owns slots 12001-14000
M5 owns slots 14001-16383
Replicas of M1:
R1a follows M1, offset 105000
R1b follows M1, offset 104700
Now suppose M1 stops responding.
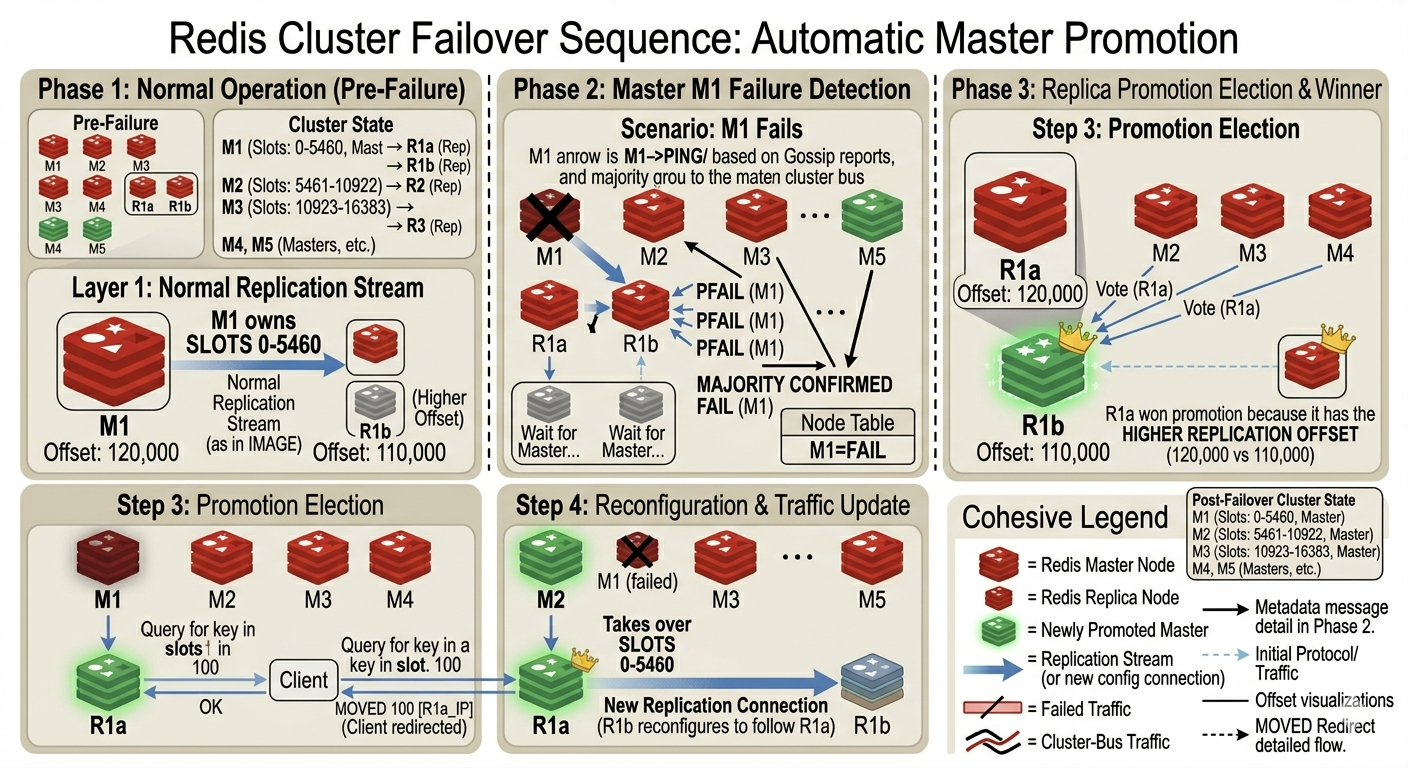
Step 1: Failure Suspicion
Failure detection starts the same way described in the gossip section. A master may stop receiving timely cluster-bus responses from M1 and mark it as PFAIL locally.
M2: M1 is PFAIL
M3: M1 is PFAIL
M4: M1 is PFAIL
These are still local suspicions. They become meaningful only as failure reports spread through gossip.
Step 2: Confirmed Failure
As failure reports accumulate, a master may collect valid reports from a majority of masters. At that point, M1 can be marked FAIL, and that FAIL state is gossiped through the cluster.
M2 receives reports from M2, M3, and M4.
Majority reached.
M2 marks M1 as FAIL and gossips the FAIL state.
The cluster can now begin failover for the slots previously served by M1.
Step 3: Replica Eligibility
The replicas of M1 evaluate whether they are eligible to replace it. A replica that is too stale, disconnected for too long, or not in a healthy replication state may be a poor candidate.
Replication offsets matter here:
R1a offset: 105000
R1b offset: 104700
R1a has consumed more of M1’s replication stream than R1b, so it is the safer candidate. Promoting R1a is likely to lose less recent data.
Step 4: Election Delay
Replicas do not all try to promote themselves at exactly the same time. Redis uses delays to reduce collisions and to give better candidates a chance to act first.
Conceptually:
R1a is more up to date -> shorter delay
R1b is further behind -> longer delay
The goal is not just to promote any replica. The goal is to promote a replica that is available and reasonably current.
Step 5: Vote Request
A replica that wants to become master requests votes from the remaining masters. The voting masters decide whether to grant the vote based on the current epoch and failover rules.
For the five-master example, a majority is three masters.
R1a requests votes from M2, M3, M4, M5.
M2 grants vote.
M3 grants vote.
M4 grants vote.
R1a has majority and can promote itself.
Votes prevent multiple replicas from safely promoting themselves for the same failed master in the same epoch. Epochs provide ordering so the cluster can distinguish older failover attempts from newer ones.
Step 6: Promotion and Slot Takeover
After winning the election, R1a promotes itself to master and claims the slots previously owned by M1.
Before:
slots 0-5460 -> M1
After:
slots 0-5460 -> R1a
This is a topology change. The promoted replica announces its new role and slot ownership through the cluster bus. Other nodes update their node tables as they receive the new state.
Step 7: Client Recovery
Clients may still have the old slot map cached.
client slot map:
slots 0-5460 -> M1
After failover, that map is stale:
actual owner:
slots 0-5460 -> R1a
When clients send requests using the old map, they may receive MOVED redirects from nodes that know the new owner. Cluster-aware clients update their slot maps and retry against R1a.
Step 8: Replica Reconfiguration
After R1a becomes the new master, the remaining replica R1b should no longer follow the failed M1. It reconfigures to follow R1a.
Before:
R1a -> follows M1
R1b -> follows M1
After:
R1a -> master
R1b -> follows R1a
The cluster has restored a writable owner for the affected slots, but it may still need operational attention: replacing the failed node, restoring replica count, and checking whether any acknowledged writes were lost.
What Failover Guarantees and What It Does Not
Redis Cluster failover is an availability mechanism. Its primary job is to restore a writable owner for the slots that belonged to the failed master.
After a successful failover, the cluster should converge on a new topology:
old owner: M1
new owner: R1a
affected slots: 0-5460
Cluster-aware clients can then refresh their slot maps, follow MOVED redirects, and continue sending commands to the new master.
That is what failover provides: a path back to serving the affected slots.
It does not provide a linearizable handoff from the old master to the new master. Redis Cluster does not prove that every write acknowledged by M1 was replicated to R1a before promotion.
If M1 acknowledged a write that had not reached R1a, that write may be absent after promotion:
Time 0: M1 applies SET cart:123 and replies OK.
Time 1: M1 fails before sending that write to R1a.
Time 2: R1a is promoted.
Result: cart:123 may be missing on the new master.
This is the asynchronous replication tradeoff from the previous section, now seen during failover:
low write latency -> possible replica lag -> possible write loss on promotion
The operational goal is not to eliminate that window inside Redis Cluster’s default model. The goal is to make it small and visible: keep replicas healthy, monitor offsets and lag, size the replication backlog appropriately, place replicas in separate failure domains, and understand which application states can be reconstructed from an authoritative system.
9. Slot Migration and Resharding
Resharding is the process of changing which masters own which slots. It is how a Redis Cluster grows, shrinks, or rebalances load without changing the key-to-slot hash function.
Why Slots Move
A cluster usually moves slots for one of three reasons:
- Adding capacity: a new master is added and existing masters give it some slots.
- Removing capacity: a master is drained before being removed.
- Rebalancing load: one master owns slots with more memory or traffic than others.
For example:
Before:
M1 owns slots 0-5460
M2 owns slots 5461-10922
M3 owns slots 10923-16383
Add new master:
M4 owns no slots yet
After rebalancing:
M1 owns slots 0-4095
M2 owns slots 5461-9550
M3 owns slots 10923-15000
M4 owns slots 4096-5460, 9551-10922, 15001-16383
The exact ranges are operational choices. The important point is that slots move; keys keep hashing to the same slots.
Moving a Slot Has Two Layers
Moving a slot is not just changing metadata. It has two layers:
- Ownership metadata: the cluster records that the target master should own the slot.
- Key migration: the actual keys in that slot move from the source node to the target node.
The metadata change is small. The key movement can be expensive.
If slot 4200 contains three small keys, migration is cheap. If it contains large values or hot keys, migration can consume network bandwidth, CPU, memory allocator work, and event-loop time.
Migrating and Importing States
Redis uses explicit migration states so the cluster can handle requests while a slot is in motion.
- Migrating: the source node is moving keys for a slot away.
- Importing: the target node is receiving keys for that slot.
For example, if slot 4200 is moving from M1 to M4:
M1: slot 4200 is MIGRATING to M4
M4: slot 4200 is IMPORTING from M1
During this window, some keys for slot 4200 may still be on M1, while others have already moved to M4.
The Key Migration Loop
At a high level, resharding tools perform a loop like this:
1. Mark slot 4200 as IMPORTING on M4.
2. Mark slot 4200 as MIGRATING on M1.
3. Ask M1 for a batch of keys in slot 4200.
4. Move those keys from M1 to M4.
5. Repeat until M1 has no more keys for slot 4200.
6. Update slot ownership so slot 4200 belongs to M4.
The Redis commands involved include:
CLUSTER SETSLOT: changes slot state or ownership metadata.CLUSTER GETKEYSINSLOT <slot> <count>: finds keys on a node for a slot.MIGRATE: moves keys from one Redis node to another.
Conceptually:
M1 GETKEYSINSLOT 4200 100
M1 MIGRATE keys -> M4
repeat until empty
CLUSTER SETSLOT 4200 NODE M4
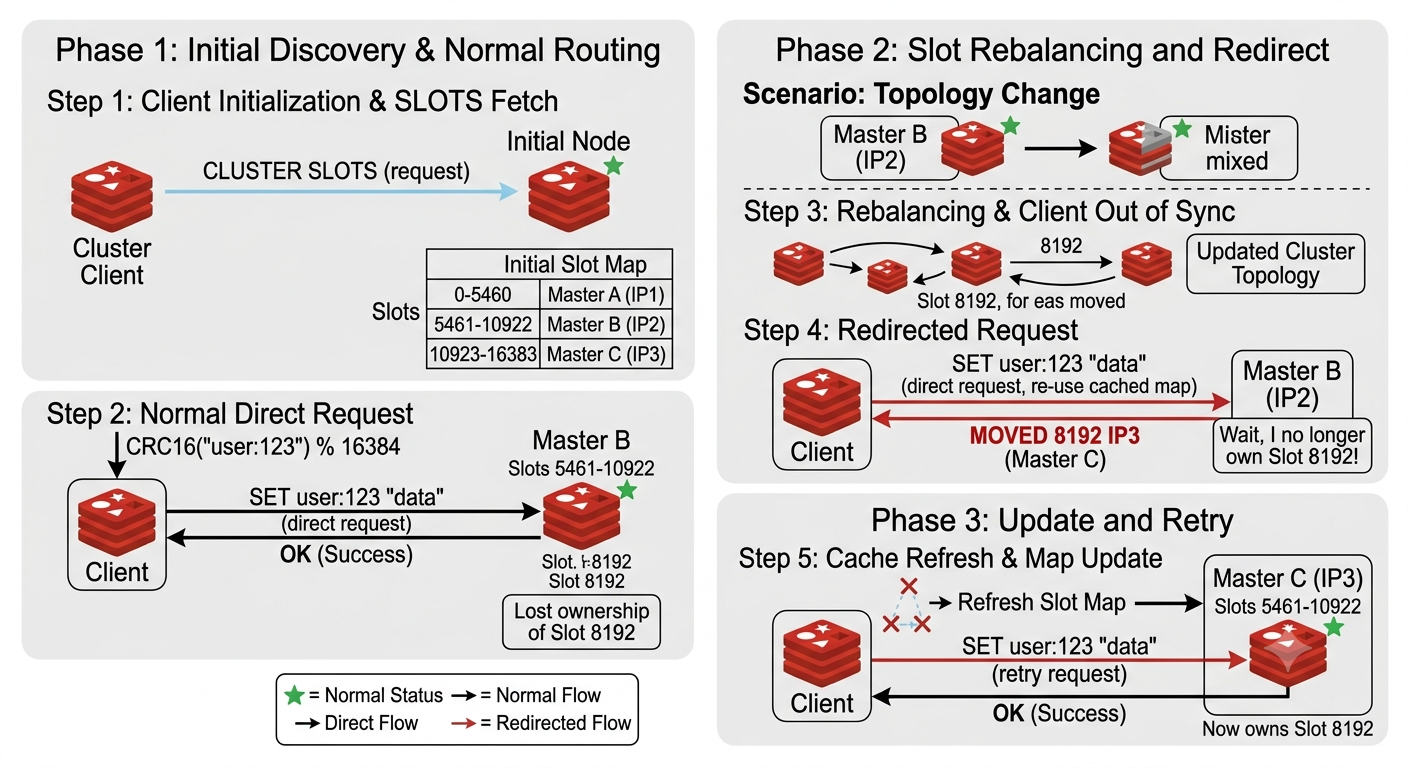
Why ASK Exists During Migration
During migration, the cluster is in an intermediate state. The source is still the official owner for the slot, but some keys may already exist on the target.
That is why Redis uses ASK.
If a client asks M1 for a key that has already moved to M4, M1 can return:
-ASK 4200 10.0.4.10:6379
The client then sends ASKING to M4 and retries the command there. This is a temporary redirect for that command only. The client should not permanently update its slot map yet, because the slot migration is not complete.
When migration finishes and slot ownership changes permanently, stale clients receive MOVED instead:
-MOVED 4200 10.0.4.10:6379
ASK is for the migration window. MOVED is for the final ownership change.
Operational Risks
Online resharding avoids a full cluster stop, but it is not free.
- Moving large values can saturate network links.
- Moving many slots in parallel can add CPU and allocator pressure.
- Migrating hot slots can increase latency on both source and target.
- Moving keys can compete with normal application traffic.
- Poorly timed resharding can turn a capacity fix into a latency incident.
Operationally, resharding should be treated like live traffic engineering. It needs batching, throttling, observability, and rollback thinking. The unit of movement is a slot, but the cost of movement is determined by the keys and traffic inside that slot.
10. Consistency and Distributed Systems Tradeoffs
Redis Cluster is best understood as an availability- and latency-oriented distributed cache. It has coordination, failover, routing metadata, and replicas, but it does not provide the same consistency model as a consensus-backed database.
The earlier sections described the mechanisms. This section names the tradeoffs those mechanisms create.
Asynchronous Replication Means Possible Write Loss
The most important tradeoff is asynchronous replication.
A master can acknowledge a write before that write reaches its replicas. If the master fails in that window, the promoted replica may not contain the acknowledged write.
Time 0: M1 accepts SET cart:123 and replies OK.
Time 1: M1 fails before R1 receives the write.
Time 2: R1 is promoted.
Result: cart:123 may be missing.
This is not a rare edge case in the consistency model. It is the direct consequence of choosing low-latency master acknowledgments instead of quorum commits.
Cluster Metadata Is Eventually Consistent
Redis Cluster metadata also converges over time.
During failover or resharding, different clients and nodes may briefly hold different views:
Client A believes slot 4200 -> M1
Client B has refreshed and knows slot 4200 -> M4
M2 has received the new topology
M5 has not received it yet
Redis handles this through gossip, epochs, and redirects. The system is designed to converge, but not every participant observes the new topology at the same instant.
This is why MOVED and ASK are part of the design rather than exceptional accidents. They are how Redis corrects stale views while keeping the normal request path direct.
What Split-Brain Means
Split-brain is a failure mode where two parts of a distributed system both believe they are allowed to act as the authority for the same data.
In Redis Cluster terms, the dangerous version would be two nodes both believing they are the master for the same slots and both accepting writes.
For example:
Network partition:
Side A: M1 is still reachable by some clients.
Side B: replicas and other masters believe M1 has failed.
Danger:
Side A continues accepting writes on M1.
Side B promotes R1a and also accepts writes for the same slots.
Now there are two histories for the same keys. Redis Cluster does not have a consensus log that can merge those histories into one strongly ordered result.
How Redis Reduces Split-Brain Risk
Redis Cluster reduces split-brain risk with several mechanisms:
- failure must move from local
PFAILsuspicion to majority-confirmedFAIL, - replicas need authorization through failover voting,
- configuration epochs help order competing topology claims,
- clients are redirected toward the node the cluster believes owns a slot,
- minority partitions are limited in their ability to complete failover.
These mechanisms make accidental dual ownership less likely, but they are not the same as linearizable consensus. Redis Cluster is designed to recover availability quickly with bounded coordination, not to serialize every state transition through a globally replicated log.
CAP in Practical Terms
The CAP theorem is often discussed too abstractly. For Redis Cluster, the practical version is this:
When the network is healthy, Redis Cluster gives fast single-master writes for each slot and asynchronous replication to replicas.
When failures or partitions happen, Redis prefers restoring service for affected slots over guaranteeing that no acknowledged write can ever be lost. It uses quorum-like failover mechanics to reduce unsafe promotions, but it does not provide strongly consistent writes across replicas.
The tradeoff is deliberate:
lower write latency
smaller operational surface
automatic failover
|
v
weaker consistency than consensus-backed databases
Comparison With Other Systems
Compared with Raft-based systems, Redis Cluster avoids a consensus round on every write. That keeps writes fast, but it means acknowledged writes can be lost during failover.
Compared with Memcached, Redis Cluster adds native partitioning, replication, redirects, and failover. The cost is more cluster coordination and more client responsibility.
Compared with globally distributed databases, Redis Cluster is not trying to provide multi-region serializability or conflict resolution. It is a low-latency distributed cache architecture, usually deployed close to the applications that use it.
Operational Rule of Thumb
Redis Cluster is a strong fit when the application can tolerate one of the following:
- cached data can be rebuilt from an authoritative system,
- small windows of stale or lost cache state are acceptable,
- the application has its own idempotency or reconciliation logic,
- low latency matters more than strong write durability.
It is a poor fit when Redis itself must be the only durable source of truth for critical state that cannot be lost or reconstructed.
11. Cross-AZ and Multi-Region Deployments
Redis Cluster placement should be designed around failure domains. The two common questions are different:
- Should replicas be placed across availability zones inside one region?
- Should one Redis Cluster span multiple geographic regions?
The first is usually yes. The second is usually no.
Cross-AZ Within One Region
Cross-AZ placement is the normal high-availability pattern for Redis Cluster.
A master and its replicas should not sit in the same failure domain. If M1 runs in AZ-a, its replica should be in AZ-b or AZ-c.
AZ-a: M1
AZ-b: R1a
AZ-c: R1b
If AZ-a fails, the cluster still has replicas outside the failed zone. One of those replicas can be promoted, and clients can converge on the new owner through updated slot maps and redirects.
The tradeoff is latency. Cross-AZ replication is usually acceptable because zones within a region are designed for relatively low-latency communication. Replication lag may increase compared with same-AZ placement, but the availability gain is usually worth it.
Why Multi-Region Is Different
Spanning one Redis Cluster across regions is a different problem.
Regions have much higher and more variable latency than availability zones. That affects Redis Cluster in several ways:
- replication lag increases because writes must cross a WAN,
- cluster-bus gossip becomes slower and noisier,
- failure detection becomes harder to tune,
- transient WAN issues can look like node failures,
- failover decisions become more vulnerable to partitions,
- split-brain risk becomes harder to reason about.
For example, if a Redis Cluster spans London and Virginia, a temporary network issue between regions may cause each side to see the other as unhealthy. Redis Cluster’s gossip and failover model was not designed to make low-latency cache decisions across that kind of WAN boundary.
Recommended Multi-Region Pattern
For most systems, the safer pattern is region-local Redis Clusters:
Region eu-west:
app -> local Redis Cluster
Region us-east:
app -> local Redis Cluster
Each region keeps cache access close to the application. The authoritative database, event stream, or application layer handles cross-region consistency.
This model treats Redis as a regional acceleration layer, not as the global source of truth.
Disaster Recovery
Disaster recovery is usually handled outside the Redis Cluster control plane.
Common patterns include:
- rebuilding cache state from the authoritative database,
- using persistence snapshots or backups where appropriate,
- warming a standby regional cache,
- replaying events from a durable stream,
- using managed Redis products with explicit cross-region replication features.
Redis Enterprise and some managed Redis offerings provide additional multi-region capabilities, including CRDT-based conflict resolution in specific configurations. Those systems have different tradeoffs from open-source Redis Cluster and should be evaluated as separate architectures.
12. Operating Redis at Scale
Operating Redis Cluster well is mostly about keeping the theoretical tradeoffs visible in production. Hot keys, replica lag, stale client topology, memory pressure, and resharding load all show up as latency before they show up as clean failures.
Watch the Right Unit of Load
Cluster averages are often misleading. A Redis Cluster can look healthy overall while one master is saturated because it owns a hot slot or a hot key.
Useful signals include:
- per-node CPU,
- per-node network throughput,
- command latency by node,
- memory usage by node,
- evictions by node,
- hot key and hot slot distribution,
- client-side redirect rates.
The operational question is not only “is the cluster busy?” It is “which node, slot, tenant, or key is carrying the load?”
Detect Hot Keys Early
Hashing spreads keys, not demand. A single key such as checkout:new-flow, product:viral-item, or tenant:large-customer:config can dominate one master.
Common mitigations include:
- splitting a hot logical key into multiple physical keys,
- adding local in-process caching for extremely hot read-only values,
- using request coalescing so many callers do not rebuild the same value,
- moving highly contended workflows out of Redis if they need stronger coordination,
- reviewing hash-tag usage to avoid forcing too much traffic into one slot.
Hot-key handling is application-specific. Redis Cluster can distribute ownership, but it cannot make an uneven workload uniform by itself.
Size Replication Backlogs Deliberately
The replication backlog determines how much history a master can replay to a reconnecting replica.
If the backlog is too small, brief network interruptions can force full resyncs. Full resyncs are expensive and can create secondary incidents through CPU, memory, and network pressure.
The backlog should be sized with real write volume and expected interruption windows in mind:
required backlog window ~= write throughput * tolerated disconnect duration
The goal is not to make full resync impossible. The goal is to make partial resync likely for normal transient failures.
Treat Resharding as Live Traffic Engineering
Resharding moves real keys through the same infrastructure serving application traffic. It should be planned and throttled.
Operationally, that means:
- move slots in batches,
- avoid migrating many hot slots at once,
- watch source and target node latency,
- watch network saturation,
- pause or slow migration if application latency rises,
- avoid large resharding operations during peak traffic.
The cluster may support online migration, but “online” does not mean “free.”
Tune Failure Detection to the Network
cluster-node-timeout controls how quickly Redis starts treating missed communication as suspicious. If it is too low for the environment, transient network jitter can become false failure detection. If it is too high, real failures take longer to recover.
The right value depends on:
- cross-AZ latency,
- normal packet loss or jitter,
- instance pause behavior,
- expected failover objectives,
- tolerance for false positives.
Failover settings should be tested under realistic network impairment, not chosen only from defaults.
Make Clients Part of the Reliability Model
Redis Cluster clients are not passive TCP wrappers. They cache slot maps, follow redirects, retry commands, and refresh topology.
Production client behavior should be checked explicitly:
- Does the client refresh topology after
MOVED? - Does it handle
ASKcorrectly during migration? - Are retries bounded?
- Are connection pools sized per node rather than only per cluster?
- Does the client expose redirect and retry metrics?
Many Redis Cluster incidents are client behavior incidents: stale topology, retry storms, uneven connection pools, or clients that do not fully support cluster semantics.
Prevent Cache Stampedes
A cache miss can become a backend outage if many clients rebuild the same value at once.
Common patterns include:
- request coalescing,
- lock-based rebuilds,
- refresh-ahead,
- stale-while-revalidate,
- TTL jitter to avoid synchronized expiration,
- per-key rebuild rate limits.
Redis Cluster solves distributed ownership. It does not automatically solve workload collapse when many clients miss the same key at the same time.
Monitor the Failure Path, Not Just the Happy Path
The important dashboards are not only throughput and memory.
A production Redis Cluster should expose:
- replication offsets and lag,
- connected replica count,
- backlog size and utilization,
- full resync count,
- partial resync success rate,
PFAILandFAILevents,- failover duration,
- slot migration progress,
MOVEDandASKrates,- evictions and expired-key behavior,
- per-command latency percentiles.
The goal is to know whether the cluster can survive the next failure, not just whether it is serving traffic now.
Capacity Planning
A Redis Cluster should not be sized only for average memory usage.
Capacity planning should leave room for:
- replica overhead,
- fragmentation,
- backlog memory,
- resharding headroom,
- failover load after a master disappears,
- traffic spikes,
- full resync events,
- uneven slot or tenant distribution.
The practical target is boring headroom. Redis is usually placed on latency-sensitive paths; running it near saturation leaves little room for failure recovery.
13. Conclusion
Redis Cluster is a decentralized distributed cache architecture built around a small set of core ideas: fixed hash slots, client-side routing, node-to-node gossip, asynchronous replication, and replica promotion.
Those choices keep the common request path short. A cluster-aware client can compute a key’s slot, look up the slot owner, and send the command directly to the responsible master. Topology changes are handled through metadata propagation, redirects, slot movement, and failover rather than through a central coordinator on every request.
The tradeoff is weaker consistency than a consensus-backed database. Replication is asynchronous, metadata converges over time, and failover can lose writes that were acknowledged by a failed master but not yet received by the promoted replica. Redis Cluster reduces these risks with gossip, epochs, voting, replicas, and client redirects, but it does not remove them.
A production Redis Cluster should therefore be treated as distributed infrastructure, not just a faster key-value process. Correct operation depends on slot distribution, client behavior, replica health, backlog sizing, failure-domain placement, resharding discipline, and observability of the failure path.
The design is most appropriate when Redis is used as a low-latency cache or derived-state layer whose contents can be rebuilt or reconciled from an authoritative system. It is a poor substitute for a strongly consistent primary database when acknowledged writes must never be lost.
Leave a Comment