Design Web Crawler
Published:
Features to support:
- Politeness/crawl rate: respect the upper limit of visit frequency of sites
- DNS Query
- Distributed Crawling
- Priority Crawling
- Duplication Crawling
Capacity Estimation
Consider total web pages: 15 Billion
We can crawl those pages in one month:
15 billion * (4 weeks * 7 days * 86400 seconds) ~ 6200 pages/sec
- Assume the size of each page:
100 KB - Metadata size:
500 bytes per page
Total size:
\[15 * 10^9 pages * (100 * 10^3 + 500) bytes \rightarrow 1.5 * 10^{15} \rightarrow 1.5 PB\]
We assume that our storage is only 70% consumed
1.5 PB / 0.7 ~ 2.14 PB
High-Level Design
- Pick a URL from the unvisited URL list
- Determine the IP address of the URL
- Connect with the host and download the content
- Parse the content and filter the URLs
- Add the new URLs to the unvisited list
- Process the downloaded content: store or index its content
Architecture
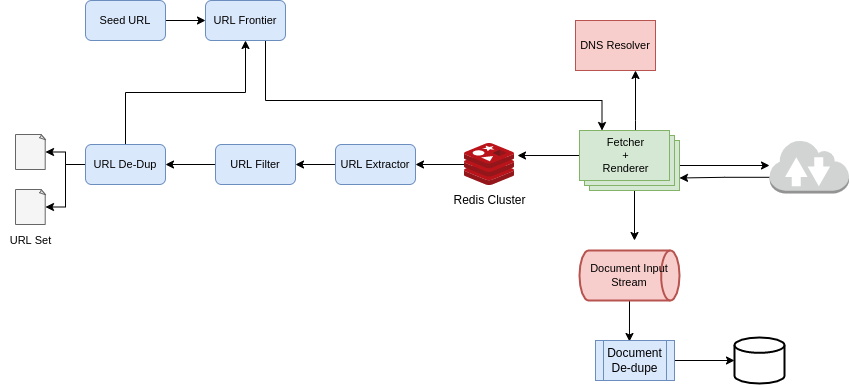
Services
Seed URLs: The list of URLs from which the web crawler will start to crawl the web pages. This can be a list of highly visited sites like yahoo, google, CNN, etc.
URL Frontier: URL Frontier contains the list of URLs that are not visited yet by the crawler.
- Fetcher+Renderer:
- Multithreaded set of a cluster that fetches the web pages from the web.
- Pages are generally not static. There are generally scripts like JS, Ajax on the web pages. Therefore a renderer is required that executes these scripts on the server-side to generate the complete webpage.
- DNS Resolver:
- To fetch a document, Hostnames need to be mapped to IP address.
- For the IP lookup instead of sending a request to an external DNS server, an internal resolver can be used to reduce the latency.
- Document Input Stream:
- Threads forward the downloaded document to Document Input Stream.
- Document is cached in a
Rediscluster for further processing - The document is processed for duplication checks and compressed and stored in a database like
BigTable - Document De-dupe Module:
- The document is checked whether its content has been previously seen.
- If the document is previously seen it is discarded and not stored.
- If this is a fresh document, it is compressed and stored in the database.
- Fingerprint mechanisms like
checksumorshinglescan be used to detect duplication
- URL Extractor:
- A copy of the document from the
Rediscache is fed to the extractor. - The extractor will parse the network protocol and extract all the links.
- The links are converted to absolute URLs.
- A copy of the document from the
- URL Filter:
- The URL filter provides a customizable mechanism for controlling the URLs to be crawled.
- The crawler can be restricted to crawl on certain formats like jpg, png, etc. while discarding formats like mp3, etc.
- The robot exclusion protocol restricts the web pages for a crawler. This can be done by the URL filter.
- URL De-dupe test:
- Most of the pages contain URLs that are already seen by the crawler.
- Already crawled URLs can be maintained in a data store based on the domain name.
- The duplication test can be either done by checking the checksum instead of string comparison or using Bloom filters.
Prioritization and Politeness
The prioritization and politeness are implemented in the URL Frontier module as it provides the list of URLs to the fetchers. Priority of webpages can be decided by:
- quality of the webpage
- rate of change of webpage
Spam webpages change their contents frequently that is why we also need to check the quality of the webpages. For a news page that updates content frequently, the crawler will need to recrawl the link every few minutes to incorporate any changes.
Politeness
- Crawler should ensure that it does not overwhelm the host’s server at any point in time
- Single connection should be open between host and crawler
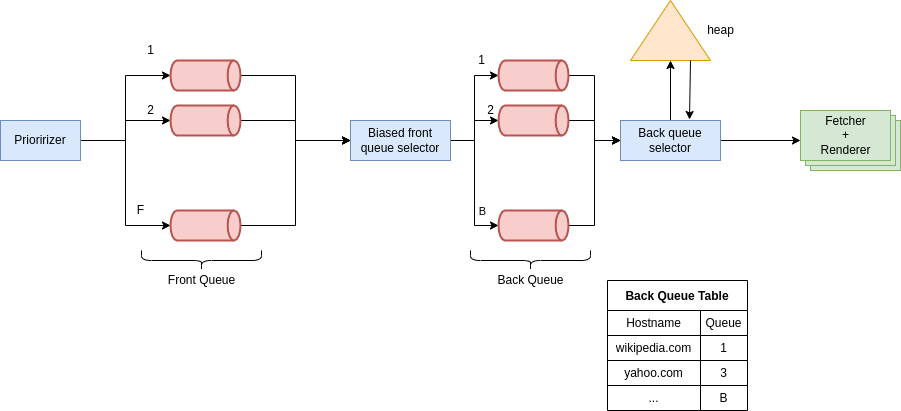
Two queues are maintained by the URL frontier.
- Front Queue:
- They implement the prioritization.
- Number of front queues depends on the prioritization. For now, we assume there are F front queues.
- Back Queue:
- They implement politeness.
- The number of back queues depends upon the number of threads running in the fetcher. Every queue is mapped to one and only one thread.
- Each back queue can contain URLs from a single domain only. This ensures that the thread responsible for that queue will open only one connection with the host.
Biased Front Queues Selector:
- The URLs are pushed from the front queue to the back queue by the selector. It is biased as it picks the highest priority URLs
Back Queue Table:
- Back Queue table is maintained to map the Hostname with the queue number
- When the back queue becomes empty, the biased front queues selector picks up URLs from a different domain and inserts them into the back queue. The queue table is updated with the new hostname.
Back Queue Heap:
- Each back queue has a min-heap maintained.
- The priority of the heap is according to the politeness (next visit time)
- for every visit to the host by the crawler, it updates the next visit time according to the politeness and inserts it into a heap.
- When the fetcher is done with a URL it asks for the next URL from the Back queue selector. The back queue selector picks up the queue number from the min-heap whose time has to visit has elapsed.
- This helps the crawler in respecting the politeness of the host
Leave a Comment