SSTable
Published:
SSTable stands for Sorted String Table.
An SSTable is an immutable, sorted on-disk map of key -> value records.
SSTables are a core building block in LSM-tree based systems like Bigtable, Cassandra, HBase, LevelDB, and RocksDB.
When an in-memory memtable crosses a threshold, it is flushed to disk as a new SSTable.
Why SSTables Exist
A B-Tree style update does random writes in-place. SSTables avoid this by converting random writes into sequential appends plus background merge work.
SSTables optimize for:
- Fast sequential writes
- High write throughput
- Ordered range scans (
key1..key2) - Deterministic cleanup via compaction
Trade-off:
- A read may check multiple files
- Background compaction is mandatory
End-to-End Data Flow
For every mutation (key, value, timestamp):
- Append to
WALfor durability - Insert into
memtable(sorted structure in memory) - ACK client after WAL + memtable update
- Flush memtable to new SSTable when memory threshold is reached
- Compact SSTables in background to remove stale versions
SSTables are immutable after creation. New writes never modify an existing SSTable.

SSTable File Layout
At a practical level, one SSTable usually contains:
Data blocks(sorted records, often compressed block-by-block)Primary index(block key boundaries -> block offsets)Index summary(sampled primary index entries kept in memory)Bloom filter(fast negative lookup)Metadata(min/max timestamp, tombstone stats, compression/checksum info)
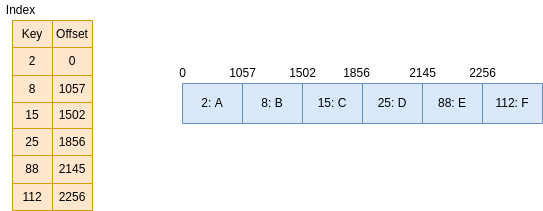
For hot point reads, many systems also use:
Key cache: key -> data offsetChunk/block cache: recently read data blocks in memory

Each data block stores records in sorted key order. A common per-record shape is:
key_lengthvalue_length(or tombstone marker)timestamp/sequencekey bytesvalue bytes
Implementations usually apply prefix compression inside blocks:
- store shared prefix length with previous key
- store only non-shared suffix
- place restart points every N keys for binary search
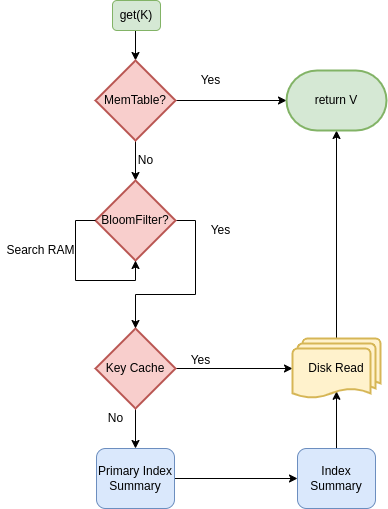
Read Path
For a point lookup of key k:
- Check
memtable - Check immutable memtables waiting for flush
- Search SSTables in recency order (newest first):
- Test Bloom filter
- If Bloom says
no, skip this SSTable - If Bloom says
maybe, probe index summary - Read target section of primary index
- Seek target data block and binary search inside block
- Stop at first visible version for the read timestamp/snapshot
If latest version is a tombstone, the key is deleted from reader perspective.
Range Scans
Range reads (startKey..endKey) use iterators from:
- memtable
- immutable memtables
- every overlapping SSTable
These iterators are merged with a min-heap by key, while applying:
- latest-version wins
- tombstone suppression
- snapshot timestamp visibility rules
WAL, Flush, and Recovery Semantics
WAL provides durability for memtable state not yet flushed.
A typical sequence:
- Append mutation to WAL segment
- Insert mutation in memtable
- Rotate memtable when full
- Flush immutable memtable to SSTable
- Mark old WAL segments as recyclable after all their data is persisted
Crash recovery:
- Load existing SSTables
- Replay non-obsolete WAL segments
- Rebuild memtable in key order
Deletes, Tombstones, and TTL
SSTables are immutable, so delete is represented as a tombstone record.
A tombstone can only be removed during compaction when it is safe:
- all older values for that key are known to be covered by compaction scope
- grace period or replication constraints are satisfied
- snapshot readers that still need old versions are not violated
TTL expiration is also enforced lazily:
- reads can ignore expired cells
- compaction physically drops expired records
Compaction Internals
Compaction is a sorted merge of SSTable inputs into new SSTable outputs.
During merge, compaction:
- Reads multiple sorted iterators
- Resolves same-key conflicts by timestamp/sequence number
- Drops shadowed values and obsolete tombstones
- Rebuilds new Bloom filters and indexes
- Atomically swaps old files with compacted files

Compaction policy affects amplification:
Size-tiered (STCS): fewer compaction rewrites, higher read amplificationLeveled (LCS): stricter level size limits, lower read amplification, higher write amplification

Read, Write, and Space Amplification
Three metrics control production behavior:
Read amplification: number of files/blocks touched per readWrite amplification: bytes rewritten by compaction per byte ingestedSpace amplification: extra disk due to multiple versions and tombstones
You reduce one by increasing another. There is no free configuration.
Worked Example
Assume key user:42 has the following versions:
SSTable-5(newest):user:42 -> tombstone @ ts=120SSTable-4:user:42 -> "gold" @ ts=110SSTable-2(oldest):user:42 -> "silver" @ ts=90
Point read for user:42:
- memtable miss
- check
SSTable-5Bloom -> maybe - probe index summary + primary index -> locate block
- read block, find tombstone at
ts=120 - stop search, return
not found
Even though older SSTables contain values, they are shadowed by the tombstone.
Now assume compaction merges SSTable-5, SSTable-4, and SSTable-2:
- compare records by key and timestamp
- keep only newest logical state
- if tombstone is still within grace window, keep tombstone in output
- if grace window is over and all older data is covered, drop tombstone and older values
Post-compaction possibilities:
- output keeps tombstone (safe but uses extra space)
- output removes all versions of
user:42(fully reclaimed)
The second case improves both read and space amplification, but only when correctness constraints are met.
Worked Example: Range Scan Merge
Range query: user:40 to user:45
Streams visible to query:
- memtable:
(user:41, "A", ts=130),(user:44, null, ts=131) - SSTable-6:
(user:40, "X", ts=120),(user:44, "M", ts=100) - SSTable-3:
(user:42, "B", ts=90),(user:45, "C", ts=95)
Merge steps:
- heap picks smallest key among stream heads
- for same key, highest timestamp wins
- tombstone winner suppresses older values
- advance only streams that contributed the emitted/suppressed key
Final scan output:
user:40 -> Xuser:41 -> Auser:42 -> Buser:44is deleted (tombstone at ts=131 wins)user:45 -> C
This is the same logical rule as point read, but applied continuously across ordered iterators.
Operational Failure Modes
Common production issues around SSTables:
Compaction debt: flush produces SSTables faster than compaction can merge themBloom filter under-provisioning: too many false positives increase disk seeksLarge partition/hot key: one key range dominates IO and compaction costTombstone accumulation: delayed cleanup hurts reads and disk usageWrite stalls: memory and flush queues fill, forcing foreground backpressure
Signals to watch:
- pending compaction bytes/tasks
- read p99 with Bloom false-positive rate
- number of SSTables touched per read
- tombstone scan/drop metrics
- flush latency and stall time
TypeScript Reference Snippets
Sparse index lookup in one SSTable
type IndexEntry = {
firstKey: string;
lastKey: string;
blockOffset: number;
};
export function findCandidateBlock(index: IndexEntry[], key: string): number | null {
let lo = 0;
let hi = index.length - 1;
while (lo <= hi) {
const mid = (lo + hi) >> 1;
const e = index[mid];
if (key < e.firstKey) hi = mid - 1;
else if (key > e.lastKey) lo = mid + 1;
else return e.blockOffset;
}
return null;
}
Compaction merge with tombstone handling
type Row = {
key: string;
value: string | null; // null => tombstone
ts: number; // larger is newer
};
export function compactSortedStreams(a: Row[], b: Row[]): Row[] {
const out: Row[] = [];
let i = 0;
let j = 0;
const emitNewest = (x: Row, y: Row) => {
const newest = x.ts >= y.ts ? x : y;
if (newest.value !== null) out.push(newest);
};
while (i < a.length && j < b.length) {
if (a[i].key < b[j].key) {
if (a[i].value !== null) out.push(a[i]);
i++;
continue;
}
if (a[i].key > b[j].key) {
if (b[j].value !== null) out.push(b[j]);
j++;
continue;
}
emitNewest(a[i], b[j]);
i++;
j++;
}
while (i < a.length) {
if (a[i].value !== null) out.push(a[i]);
i++;
}
while (j < b.length) {
if (b[j].value !== null) out.push(b[j]);
j++;
}
return out;
}
K-way merge iterator shape for range scan
type KV = { key: string; value: string | null; ts: number };
type Stream = Iterator<KV>;
export function* mergeStreams(streams: Stream[]): Generator<KV> {
const heads: Array<{ i: number; v: KV }> = [];
for (let i = 0; i < streams.length; i++) {
const n = streams[i].next();
if (!n.done) heads.push({ i, v: n.value });
}
while (heads.length > 0) {
heads.sort((a, b) => (a.v.key === b.v.key ? b.v.ts - a.v.ts : a.v.key.localeCompare(b.v.key)));
const top = heads.shift()!;
if (top.v.value !== null) yield top.v;
const next = streams[top.i].next();
if (!next.done) heads.push({ i: top.i, v: next.value });
}
}
Tuning in Practice
Memtable size: larger memtables reduce flush frequency but increase recovery replay timeBloom filter bits/key: lower false-positive rate improves read latency but costs RAMBlock size: larger blocks improve throughput; smaller blocks improve point lookup precisionCompression: reduces IO and storage; increases CPUCompaction concurrency: too low causes backlog, too high competes with foreground trafficTombstone grace/TTL: aggressive cleanup reduces space, but must respect replication/read-repair guarantees
Summary
SSTables are immutable sorted files designed for LSM storage engines. Their performance comes from sequential writes, indexed block reads, Bloom filter pruning, and continuous compaction. Most production tuning is the art of balancing read, write, and space amplification against workload shape.
Leave a Comment