Replication
Published:
Each node that stores a copy is called a replica. With multiple replicas, the challenge arises in how to ensure that all the data ends up on all replicas.
Leaders and Followers
- One of the replicas is elected as
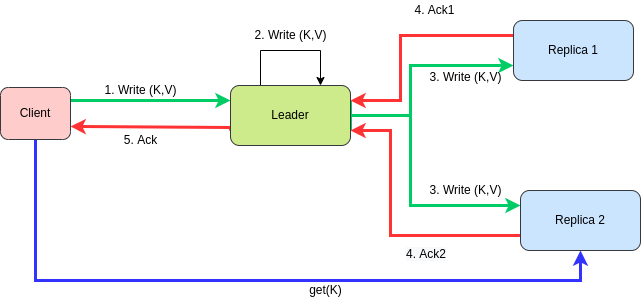
leader. When clients want to write data they send their requests toleader, which firsts write the new data to its local storage. - Other replicas as called
followers. Whenever the leader writes new data to its local storage, it also sends the data change to all its followers as a part of areplication log. Each follower takes the log from the leader and updates its local copy of the data. - Generally all the write requests are sent to users and read requests can be sent to any follower.
Asynchronous vs Synchronous Replication
- Synchronous:
- The leader responds to the client with successful write only if it has received ACK of writes from all the followers. In this way, it ensured that all the replicas contain the same data as the leader and any read request to any replica will always return the most up-to-date values.
- The problem with this approach is that, if a follower crashes or is disconnected due to network issues, the leader is kept waiting for the ACK to write.
- Receiving ACK from all the followers makes the writes slower.
- Asynchronous:
- The leader responds to the client that the write is successful without waiting for followers for the ACK.
- Writes are quite fast
- If the leader fails and is not recoverable, any writes that have not yet been replicated by the followers are lost. Writes are not durable, even if it has been confirmed to the client.
Log Replication
- In the case of log-structured storage engines (SSTables), this log is the main place of storage. Logs are compacted and garbage-collected in the background from time to time.
- In the case of B-Tree, which overwrites individual disk blocks, every modification is first written into write-ahead-logs so that the index can be restored in case of a crash
When the leader receives a write request it writes it to append-only logs for both SSTables and B-Tree. These logs are forwarded by the leader to replicas. The followers can then execute these logs to build the replica and keep it in sync with the leader.
Leaderless Replication
In leaderless implementations, the client directly sends its write to several replicas, while in some cases to a coordinator node. However, unlike the leader, the coordinator node does not enforce a particular ordering of writes.
Cassandra, Dynamo are some of the databases that use leaderless replication
Read/Write Operations
write
The client can forward the write to multiple replicas in parallel. If it receives ACK from a few replicas, it can move on. For example,
- if there are four replicas and clients sends a write request to all the replicas
- suppose the fourth replica goes down (rebooted/crashed/network disconnection)
- the client will receive the ACK from the three replicas
- it can assume that its write is successful even if it has not received the ACK from the fourth replica as the majority has responded with ACK.
read
Similar to the write operation, the client can send the read request in parallel to multiple replicas.
- the client must compare the values and timestamp received from all the replicas to determine which is the latest value
Read repair
Two techniques used for read repair in Dynamo styled DBs
- Read Repair: When a client receives stale data from a node, it sends a write request to that node with the most up-to-date value.
- Anti-entropy process:
- a background process runs that constantly looks for differences in the data between nodes and copies any missing data from one node to another
- without an anti-entropy mechanism, values that are rarely read may be missing from nodes
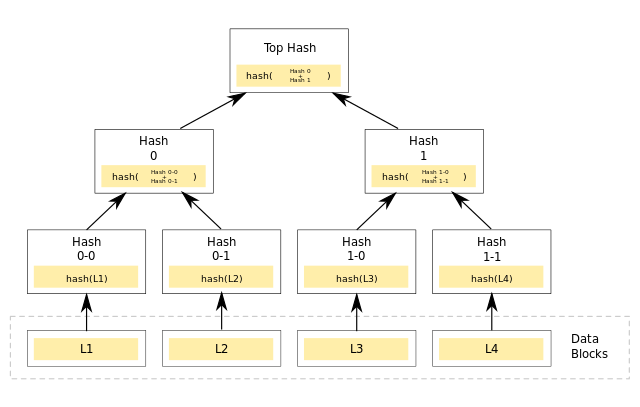
Merkel treeare used for comparing nodes
Merkel Trees A Merkel tree is a tree in which a leaf is a cryptographic hash of a data block, and every non-leaf node is labeled with the cryptographic hash of the labels of its child.
Quorums
If there are N nodes,
- every write must be confirmed by
wnodes to be considered successful - every read must query
rnodes
such that
w + r > N
This ensures that the read is performed from at least one node that has seen the most write.
Generally, the read/write requests are sent to all the N nodes. The quorum parameters indicate how many ACKs should the client wait for to consider its read/write operation successful.
Sloppy Quorum and Hinted Handoff
When the data is partitioned each node is assigned a particular range for which it can read/write. This data is replicated across other nodes.
- Suppose some of the nodes designated to store data X are down.
- The quorum for write is not reached. Instead of rejecting the write as unsuccessful to the client, the database can ask other nodes(not designated to store X) to store the data temporarily till the designated nodes come up.
Multi-datacenter Operations
Leaderless replication is suitable for multi-datacenter operations.
- the number of nodes
Nincludes all the nodes in every data center - each write from the client is sent to all the
Nnodes - client only waits for the ACKs from the quorum of nodes in the local datacenter, so that the network delay and interruptions between datacenters do not affect to operation
- The higher-latency writes happens asynchronously in the background
Consistency Level
For every read request, read-repair is performed. It can be done across data centers as well
- ONE :
- the data is returned to client from a single node.
- very fast but high probability of stale data
- QUORUM:
- > 51% replicas ack
- high consistency as there is atleast one single node that has seen the latest write
- LOCAL QUORUM:
- > 51% replicas ack in local Data Center
- LOCAL_ONE:
- > read repair only in local Data Center
- ALL:
- Ack from all nodes
Raft

Raft is a replication protocol that works on the leader-follower principle.
- Raft is included by every server as a library
- Every request sent by the client is forwarded to the raft
- raft writes that request into its log and parallelly forwards it to other followers
- Once Acks from the majority of the followers are received (including itself), leader ACKs to a client of a successful write
- The leader then executes the command to update the key-value store
- The logs are backed up on the disk. In case of a crash, these logs are used to reconstruct the node
Leave a Comment