BigTable
Published:
It is a Consistent, Partial Fault Tolerance type database with strict consistent read/writes. It is suitable for large storage where each row is less than 10MB. It is used to store data for one of the types:
- Time Series data: chronological data
- Constant stream of writes
Use BigTable: Messaging App, Web Crawler, Analytics, Google Earth
Hbase and HyperTable databases are based on BigTable.
General Conecpts
- BigTable is a key/value store, not a relational database.
- Each table has only one index, the row key
- Rows are sorted lexicographically by row key
- Column families are not stored in any specific order.
- Columns are grouped by column family and sorted in lexicographic order within the column family.
- The intersection of a row and column can contain multiple timestamped cells
Data Model
An RDBMS database stores data as a two-dimensional entity, while big table stores data as a four-dimensional identity.
- Row Key: uniquely identifies a row
- Column Family: Represents a group of columns
- Column qualifier: column name
- Timestamp
Rows
- Rows keys are arbitrary strings with a size of 64KB.
- Every read or write to a row is atomic.
- Rows are maintained in lexicographic order by row key
The BigTable retrieves data using:
- Row key
- Row key prefix
- Range of rows defined by starting and ending row keys
Store multiple delimited values in each row key. Because the best way to query Bigtable efficiently is by row key, it’s often useful to include multiple identifiers in the row key. Row key segments are usually separated by a delimiter, such as a colon, slash, or hash symbol. Row keys should be defined such that retrieving data does not require a full table scan. For eg:

This row key design lets you retrieve data with a single request for:
- A device type
- A combination of device type and device ID


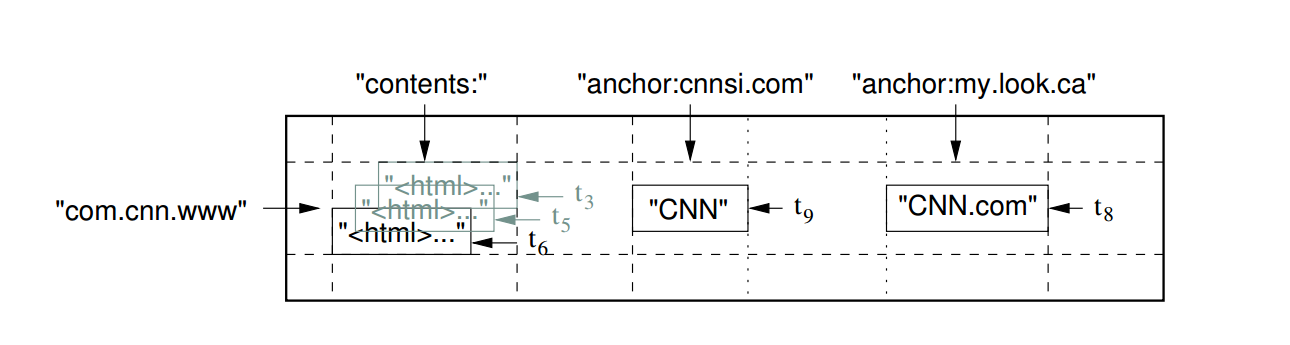
Here the row key is com.CNN.www. Content and anchor are column family. Anchor has two column qualifiers: cnnsi.com, my.look.ca. The content column has entries at multiple timestamps.
The data is indexed by
(row_key: string, column_name: string, timestamp: int64) \(\rightarrow\) cell contents (string)
Blocks
BigTable uses GFS to store Logs and data files. Internally the data is stored as SSTables. An SSTabe provides a persistent, ordered immutable map from key to values.
Internally each SSTable contains a sequence of blocks (64KB size). A block index stored at the end of the SSTable is used to locate the blocks. The block index is loaded into the memory when SSTable is opened.
To find a block: binary search is performed on the block index to locate the block offset. Then a single seek is performed, to read the block.
Implementation
A single instance of BigTable is called Cluster. Each cluster can store multiple Tables. Each table is split into multiple Tablets.
- Tablet store contiguous rows
- Each tablet is assigned to a
Tablet Server
BigTable has three major components:
- library that is linked to every client
- Single master server
- Many tablet servers: can be dynamically added or removed from the cluster
Master
Master is responsible for assigning tablets to tablet servers, detecting the addition and expiration of tablet servers, balancing tablet-server load, etc. It also handles schema changes such as table and column family creations.
Client always does not have to move through the master, thereby the load on the master is low. Clients can directly communicate with the Tablet server.
Tablet Server
Each tablet server manages multiple tablets (10 to 10000). It handles read/write requests to the tablets that it has loaded and also splits tablets when they grow too large.
Architecture
Tablet Location
Three-level-hierarchy analogous to the B+ tree is used to store tablet information.
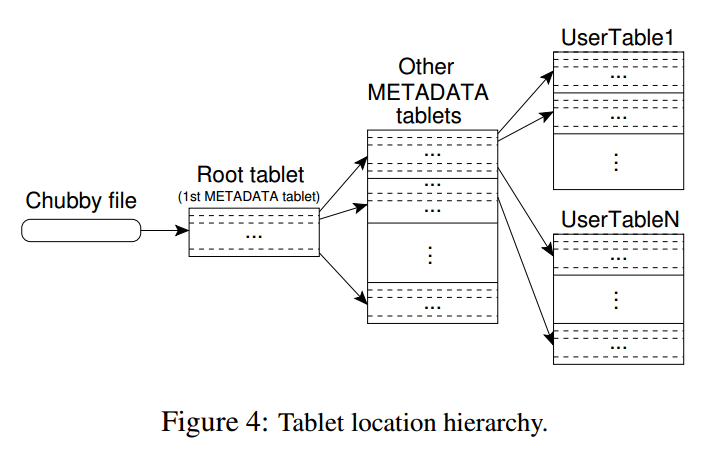
A chubby file contains the location of the root tablet. The root tablet has a special METADATA table that stores the Tablet locations. It stores the location of a tablet under a row key that is encoding of tablet's table identifier and end row
METADATA:
Key: table id + end row
Value: tablet server location
- Root Metadata tablet: This tablet is indivisible and stores the location of all the other metadata tablets.
- Other Metadata tablets: They store the location of user metadata tablets.
The client caches the information about the tablet location. If the tablet location is unknown or changed, then it recursively moves up the tablet location hierarchy.
Tablet Assignment
Each tablet is assigned to one tablet server.
Master keeps track of live tablet servers, and current assignment of tablets to tablet servers as well as unassigned tablets. BigTable uses Chubby to keep track of tablet servers.
- When a tablet server starts, it creates and acquires an exclusive lock on, a uniquely-named file in the specific chubby directory.
- The master monitors this directory to keep track of the tablet servers.
- A tablet server stops serving the tablets if it loses its exclusive lock.
- A tablet server will try to re-acquire the lock as long as the file exists. If the file does not exist then the tablet server will kill itself
- Master is responsible for detecting when a tablet server is no longer serving its tablets, and for reassigning those tablets to other servers.
- To achieve this, the master periodically asks the tablet server for the status of its lock.
- If the tablet server reports that it has lost its locks or the master is unable to reach the server, the Master attempts to acquire an exclusive lock on the server’s file. If the master can acquire the lock and Chubby is live, the Master can conclude that either the server is dead or the server is having trouble reaching the chubby.
- Master delete’s the server file and moves the associated tablets to unassigned.
To ensure that master and chubby are not vulnerable to networking issues, Master kills itself when the Chubby session expires. Cluster Management System restarts the master. On startup, master performs the following steps:
- Master grabs unique master lock in Chubby, preventing the concurrent master installation
- Master scans the servers directory of Chubby to find live servers
- Master communicates with every live tablet server to discover what tablet are already assigned to each server.
- Master scans the METADATA table to learn the set of tablets. While scanning if it encounters any tablet not assigned to any tablet server, the master adds it to the list of unassigned.
Tablet Serving
The persistent state of the table is stored in GFS. Updates are committed to a commit log that stores redo records. Of these updates, the recently committed ones are stored in memory in a sorted buffer called memtable; older updates are stored in SSTables.
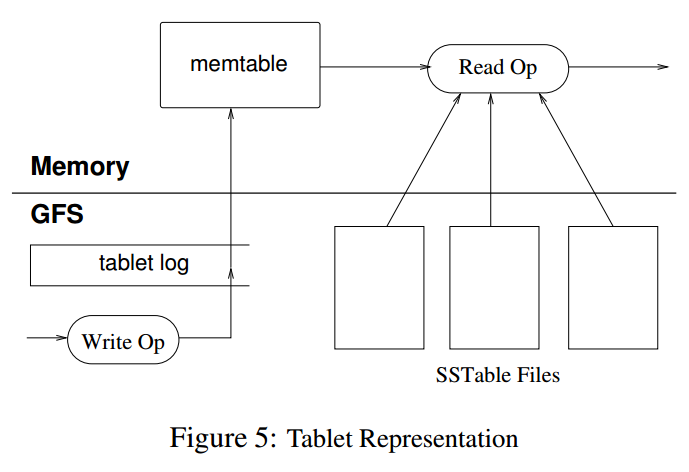
Tablet recovery
- To recover a tablet, the server reads its metadata from the METADATA table.
- This metadata contains the list of SSTables that comprise a tablet and a set of redo points, which are pointers into any commit logs that may contain data for the tablet.
- The server reads the indices of the SSTables into memory and reconstructs the memtable by applying all of the updates that have been committed since the redo points.
Write Request
- The write request arriving at the tablet server is checked if it is well-formed and writer is authorized to write.
- The mutation is written to the commit log in GFS that stores the redo logs.
- Once the mutation is committed to the commit-log, its content is stored in a sorted memory called
MemTable - After inserting into MemTable, ack is sent to the client.
- Periodically MemTables are flushed to SSTables, and SSTables are merged during compaction

Read Request
- When a read request arrives at the tablet server, it is checked for well-formedness.
- A valid read request is executed on a merged sequence of SSTable and MemTable. Since both are lexicographically sorted the view can be created efficiently.
Reference
- HBase
Leave a Comment