Google File System
Published:
Google File System
GFS is a file distributed file system that is:
- scalable
- data-intensive applications
- fault tolerent
GFS was designed by keeping in mind:
- Component failure of systems is the norm rather than an exception
- Files are huge which can run into TBs
- Files are mutated by appending data at the end. Writing between the files is very rare. The reads performed on file can be divided into two parts:
- Large streaming reads: Individual operations read a small chunk of the file may be up to 1MB. Successive operations from the same client often read through the contiguous region of a file.
- Small random reads: Typically few KB is read arbitrarily from the file. For better performance often small random reads are batched together.
GFS supports operations like create, delete, open, close, read, write on files. It further supports snapshot, record append.
- snapshot: Creates a copy of the file or directory at a low cost.
- record append: allows multiple clients to append to the same file concurrently while guaranteeing the atomicity of each append operation.
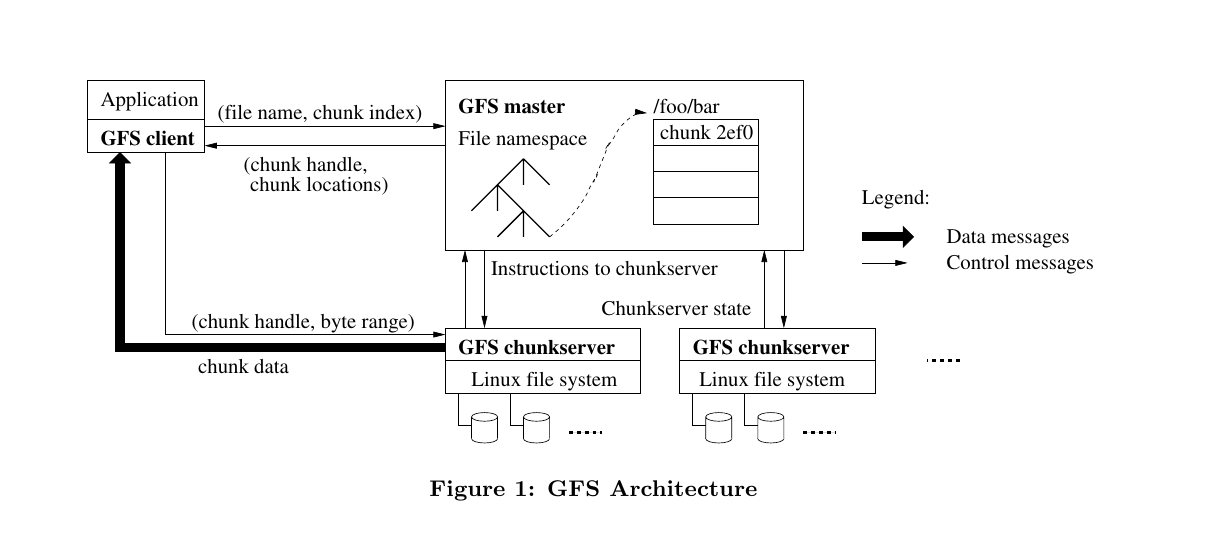
Architecture
GFS has a
- single master
- multiple chunkservers: Linux systems that store the files.
Files:
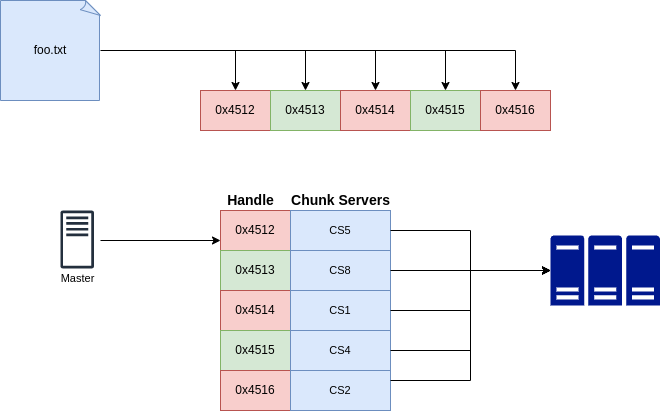
- Files are divided into fixed-size chunks. Each chunk is assigned a global, unique, immutable handle of 64 bit by the master.
- Chunkservers store the chunk on the local disk as Linux files.
They read or write chunk data specified by the handle. - For reliability, `each chunk is replicated at multiple chunk servers. By default, it’s populated in 3 chunkservers.
GFS Master:
- Master maintains all the metadata: namespace, access control, mapping from files to chunk, location of chunks, etc.
- Control system-wide activities: chunk lease management, garbage collection of orphaned chunks, chunk migration between servers
- Communicates with chunkserver with HeartBeat messages to provide instructions and collect chunkserver states.
GFS Client
- GFS client code linked into each application implements the file system APIs
- Clients interact with the master for metadata operation, but all files related communication takes place with chunkservers. The information received from the master is cached with the client for a limited period.
Chunk Size
- Each chunk is specified as constant 64 MB, which is larger than typical file system block sizes.
- Large chunk size reduces the client interaction with the chunkserver as multiple read-write on the same chunk requires only single interaction.
- It reduces the size of metadata stored at the master.
Metadata
- Master stores the following metadata in its memory:
- file and chunk namespace
- mapping from files to chunks
- location of each chunk’s replicas
- The file and chunk namespace, mapping from files to chunks are persisted by
logging mutations to an operation log storedon master’s local disk and replicas.- In case of a master’s crash the information can be retrieved from the logs.
- The location is not persisted because, on a master startup, it contacts chunkservers for the information they have about the stored chunks.
Chunk Location
- The master does not keep a persistent record of chunk locations.
- During startup it pings the chunkserver for the information about the chunks they are holding. Subsequent HeartBeat messages from the master to chunkserver help maintain the information about the state change.
Operation Logs & Checkpoint
- Operation logs contain the mutations to critical meta-data. In case of failures, these logs can restore the state of the master.
- For fault tolerance, the logs are replicated across remote machines.
- Master responds to the client only after flushing the log to the disk. The master, batches several logs files together, reducing the impact of the flushing on the throughput.
- The master recovers the file system state by replaying the logs. To minimize the startup time, the master checkpoints its state when the logs grow above a certain size. The master can load the checkpoint and replay the logs after the checkpoint to recreate the file system state and minimize the startup time.
- \[Log1 \rightarrow Log2 \rightarrow [Log1 + Log2: \textbf{Checkpoint1}] \rightarrow Log3\]
- The master can restore the state by loading Checkpoint1 and replaying the Log3
- Checkpoint is in form of B-Tree, directly mapped to memory
- Checkpoint can be saved without affecting the master’s work. When the master wants to create a checkpoint it creates a new log file and starts writing to the new log file. Master instantiates a separate thread that converts the older log files to checkpoints.
Read/Write data flow
Read
- Using the fixed chunk size, the client APIs transfer the file name and offset bytes into a chunk index within a file.
- It sends the master a request containing the file name and file offset.
- ControlMsg: Client \(\rightarrow\) Master, [filename, offset]
- Master replies with the chunk handles and a list of replicas with the latest version of the chunk.
- ControlMsg: Master \(\rightarrow\) Client, [chunk handle, chunk location]
- This information is cached at the client by filename and chunk index as a key.
- Client sends the request to replicas, probably the closest one.
- ControlMsg: Client \(\rightarrow\) ChunkServer, [chunk handle, byte-range within chunk]
- Further reads of the same chunk do not require master-client interaction until the cached information with the client expires.
Write

- Client asks Master about the file’s latest chunk.
- If Master sees chunk has no primary (or lease expired)
- if no chunkserver have the latest version #error
- pick primary P and secondaries from those latest versions
- increment version #, write to disk
- tell P and secondaries about who they are, and new version #
- replicas write new version # to disk
- Master reports back client about primary and secondary
- Client sends data to all, waits
- Client sends Primary to append
- Primary checks if the lease has not expired, and chunk has space
- Primary picks an offset (end of the chunk)
- Primary writes chunk file (Linux file)
- Primary tells each secondary the offset, tells to append to chunk file
- Primary waits for all secondaries to reply, or timeout secondary can reply “error” e.g. out of disk space.
- Primary tell Client “Ok” or “error”
- Client retries from the start if error.
Leave a Comment